pandas
分类与创建
Series
Series 是一种类似于以为 NumPy 数组的对象,它由一组数据(各种 NumPy 数据类型)和与之相关的一组数据标签(即索引)组成的。可以用 index 和 values 分别规定索引和值。如果不规定索引,会自动创建 0 到 N-1 索引。
Series 是 1 维的数据,拥有的索引,一般以竖行形式输出

创建
Series 可以方便的通过 list,array 还有 dict 来构建
pd.Series()
import numpy as np
import pandas as pd
mylist = list('abc')
myarr = np.arange(3)
mydict = dict(zip(mylist, myarr))
ser1 = pd.Series(mylist) #使用列表创建
ser2 = pd.Series(myarr) #使用数组创建
ser3 = pd.Series(mydict) #使用字典创建
print(ser1,'\n')
print(ser2,'\n')
print(ser3,'\n')
输出
0 a
1 b
2 c
dtype: object
0 0
1 1
2 2
dtype: int32
a 0
b 1
c 2
dtype: int64
在构建 Series 的时候,指定 index 来代替默认的 0~n 数字式索引
ser4 = pd.Series([100, 200, 150], index=['apple', 'banana', 'peach'])
print(ser4)
apple 100
banana 200
peach 150
dtype: int64
访问
下标方式访问
ser4['banana']
index 方式访问
ser4[1]
DataFrame
DataFrame 是一种表格型结构,含有一组有序的列,每一列可以是不同的数据类型。既有行索引,又有列索��引
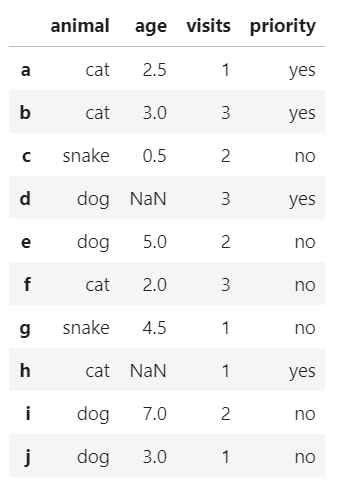
从具有索引标签的字典数据创建
data = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],
'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
df = pd.DataFrame(data,index = labels)
df
输出
从 numpy 数组创建
df2 = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),
columns=['a', 'b', 'c'])
df2
输出

df = pd.DataFrame(np.arange(9).reshape(3, 3), index = [
"Mon", "Tue", "Wed"], columns=['store1', 'store2', 'store3'])
df
输出

通过其他DataFrame来创建
df3 = df2[["a","b","c"]].copy()
df3
输出

从csv文件创建
df = pd.read_csv('path')
df = pd.read_csv('test.csv', encoding='gbk', sep=';') #分隔符为“;”,编码格式为gbk
用Series创建
s_1 = pd.Series(data['animal'])
s_2 = pd.Series(data['age'])
s_3 = pd.Series(data['visits'])
s_4 = pd.Series(data['priority'])
df = pd.DataFrame([s_1,s_2,s_3,s_4])
df
输出
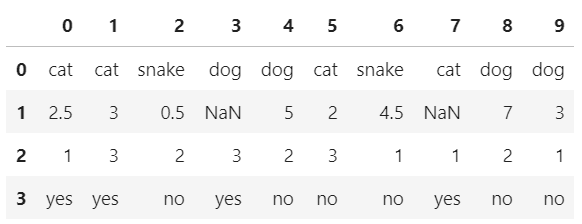
这玩意可以看做是多个 Series 的组合。DataFrame 的不同列可以是不同的数据类型,如果以 Series 数组来创建 DataFrame,每个 Series 将成为一行,而不是一列
审视
访问
以下图为例
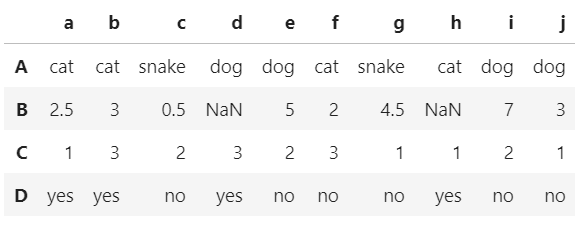
col,index 为列号和行号
colName,indexName 为具体值
df[colName]
根据列名,并以 Series 的形式返回列
若列名为默认的数字时,colName 可以被视为 col(其中就 col 可以表示为列表形式和切片形式)
df['a'] #取a列
df.a #也可
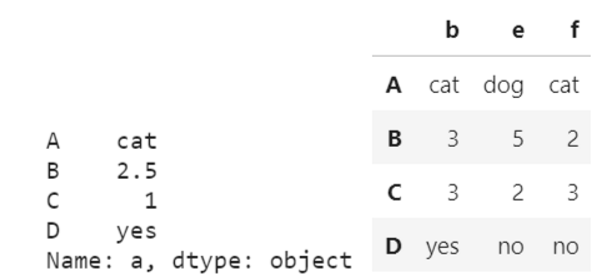
df[['b','e','f']] #取b,e,f列
输出
特殊情况下,df[colName] 可以接收行名称或者行数,但必须是切片
df[0:1] # 第1行
df[0:3] # 前3行
df['5':'5'] # 行名称为5的行
df['5':'7'] # 行名称为5的行至行名称为7的行
df[colName][indexName]
更精准的访问(几列几行)
若列名为默认的数字时,colName 可以被视为 col(其中就 col 可以表示为列表形式和切片形式)
df['c']['B']
输出
0.5
df.iloc[index, col]
其中 index,col 可以表示为列表形式和切片形式,当只传入一个参数时,该参数默认为 index
df.iloc[0:1] # 取第0行数据,较为规范
df.iloc[0] # 硬要这样俺也没办法
df.iloc[:,[2]] # 取第2列数据
df.iloc[0:3,2:6] # 取0到2行,2到5列数据
df.iloc[[0,3],[2,3,7]] # 取0和3行,2、3、7列相交数据
输出
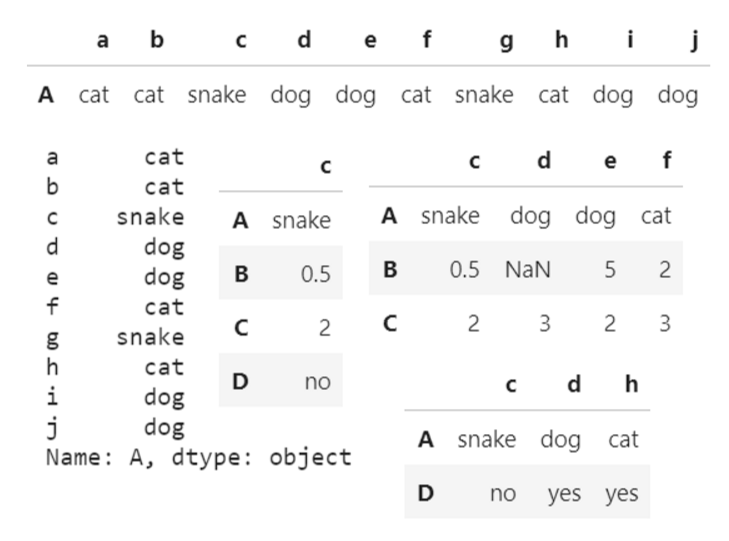
df.loc[indexName,colName]
df.iloc只能选取数据表里实际有的行和列,而df.loc可以选取没有的行和列,赋值后就可以添加新行或者列
df.loc[:,'c'] #选取c列
df.loc[['A','C'],['c','e','f']] #选取A,C列,c,e,f行相交数据
df.loc[df['c']=='snake'] #选取c列中内容为snake的行数据
输出
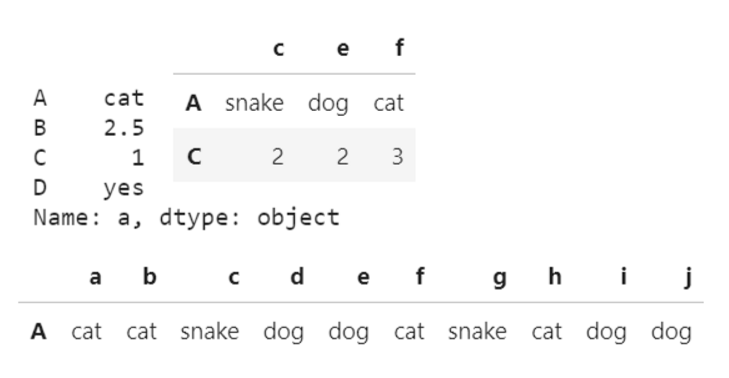
df.ix[in,co]
ix 是 loc 和 iloc 的混合,既能按索引标签提取,也能按位置进行数 据提取
筛选
df.loc[df.index[[1,3]], ['d','f']] #筛选出索引为1,3行的d,f列
df[df['d'] > 3] #筛选d(列名��)值大于3的行
df[df['d'].isnull()] #筛选d(列名)值为空的行
df['A'].isin(['cat']) #筛选A列中含有cat的行
#输出
a True
b True
c False
d False
e False
f True
g False
h True
i False
j False
Name: A, dtype: bool
df.query()
以下表为例
A B C
0 1 10 2
1 2 8 2
2 3 6 2
3 4 4 2
4 5 2 2
df = pd.DataFrame({
'A': range(1,6),
'B': range(10, 0, -2),
'C': 2
})
df.query('B == 2') # 查询B列中数值为2的行记录
df[df.A < df.B] # 查询A列数值小于B列的行记录
df.query('A < B')
df[df.B == df['C C']] # 查询B列数值和C C列相等的行记录
输出
A B C
4 5 2 2
A B C
0 1 10 2
1 2 8 2
2 3 6 2
A B C
4 5 2 2
查看
查看行数、列数
df.shape
输出
(4, 10)
查看整体信息
使用 info 函数查看数据表的整体信息,包括数据维度、列名称、数据格式和所占空间等信息
df.info()
输出
<class 'pandas.core.frame.DataFrame'>
Index: 4 entries, A to D
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 a 4 non-null object
1 b 4 non-null object
2 c 4 non-null object
3 d 3 non-null object
4 e 4 non-null object
5 f 4 non-null object
6 g 4 non-null object
7 h 3 non-null object
8 i 4 non-null object
9 j 4 non-null object
dtypes: object(10)
memory usage: 352.0+ bytes
查看数据格式
使用 dtypes 函数来返回数据格式
df.dtypes #查看数据表各列格式
df['B'].dtype #查看单列格式
输出
a object
b object
c object
d object
e object
f object
g object
h object
i object
j object
dtype: object
dtype('O')
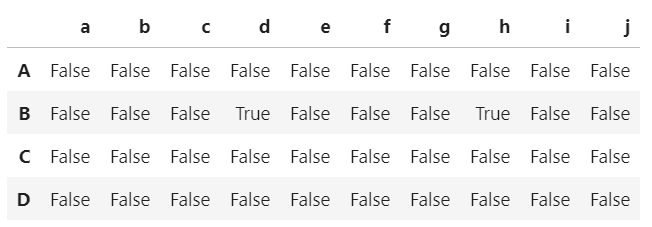
查看缺失值
df.isnull() # 检查数据空值
df['h'].isnull() # 检查特定列空值
df.isnull().sum() # 查看各列的缺失值个数
df.isnull().any() # 查看各列是否有缺失值
df.isnan() #判断nan值
输出
A False
B True
C False
D False
Name: h, dtype: bool
查看唯一值
df['a'].unique() #查看a列中的唯一值
输出
array(['cat', 2.5, 1, 'yes'], dtype=object)
查看数据表数值
df.values
输出
array([['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat',
'dog', 'dog'],
[2.5, 3.0, 0.5, nan, 5.0, 2.0, 4.5, nan, 7.0, 3.0],
[1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']],
dtype=object)
查看行、列名称
返回 Index 对象
df.columns #查看列名称
df.index #查看行名称
输出
Index(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'], dtype='object')
Index(['A', 'B', 'C', 'D'], dtype='object')
查看前后n行数据
df.head(5)
df.tail(3)
显示全部数据
# 设置行不限制数量
pd.set_option('display.max_rows',None)
# 设置列不限制数量
pd.set_option('display.max_columns',None)
统计
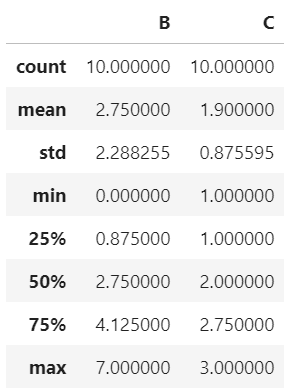
以下图为例
对数据的统计汇总
只会统计数值型数据
df.describe()
输出
排序
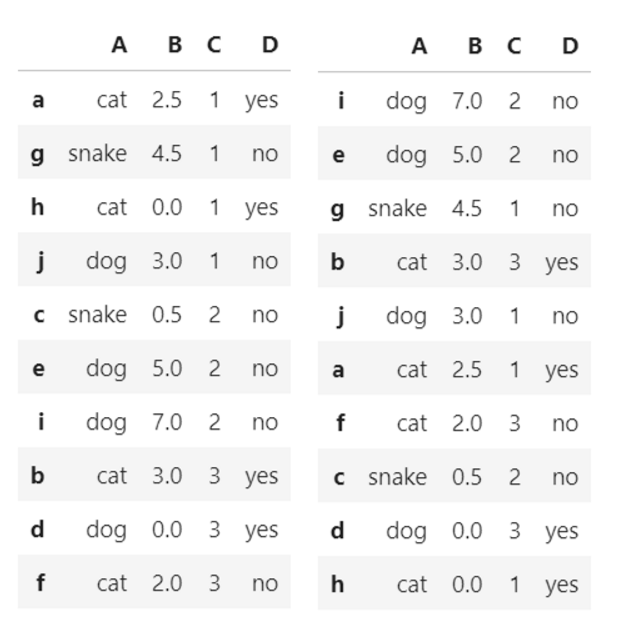
df.sort_values
df.sort_values(by=['C']) #按特定列的值升序排序
df.sort_values(by=['B'],ascending=False) #降序排序
df.sort_values(by=['B', 'C'], ascending=[False, True]) #先按B降序,再按C升序
输出
df.sort_index
按索引排序
- axis:0(跨行),1(跨列)
- ascending:0(降序),1(升序)
df.sort_index(axis=0,ascending=1) #按索引列升序排序,需要默认的索引值
输出(此处 index 设置为了’A’)

统计函数
返回 Series
max()、min()
# 使用统计函数:0 代表列求结果, 1 代表行求统计结果
data.max(0)
open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
my_price_change 3.41
dtype: float64
std()、var()
# 方差
data.var(0)
open 1.545255e+01
high 1.662665e+01
close 1.554572e+01
low 1.437902e+01
volume 5.458124e+09
price_change 8.072595e-01
p_change 1.664394e+01
turnover 4.323800e+00
my_price_change 6.409037e-01
dtype: float64
# 标准差
data.std(0)
open 3.930973
high 4.077578
close 3.942806
low 3.791968
volume 73879.119354
price_change 0.898476
p_change 4.079698
turnover 2.079375
my_price_change 0.800565
dtype: float64
median()
df = pd.DataFrame({'COL1' : [2,3,4,5,4,2],
'COL2' : [0,1,2,3,4,2]})
df.median()
COL1 3.5
COL2 2.0
dtype: float64
idxmax()、idxmin()
求索引位置
# 求出最大值的位置
data.idxmax(axis=0)
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
my_price_change 2015-07-10
dtype: object
# 求出最小值的位置
data.idxmin(axis=0)
open 2015-03-02
high 2015-03-02
close 2015-09-02
low 2015-03-02
volume 2016-07-06
price_change 2015-06-15
p_change 2015-09-01
turnover 2016-07-06
my_price_change 2015-06-15
dtype: object
其他
df.corr() #返回列与列之间的相关系数
df.count() #返回每一列中的非空值的个数
预处理
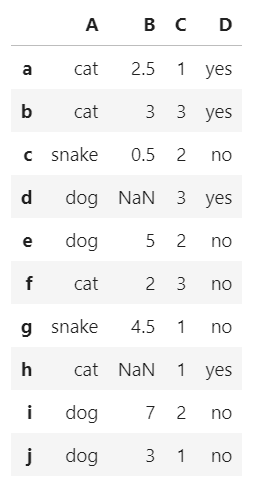
数据清理
所有函数,均返回 DataFrame 副本,不赋值不会生效
以下图为例
缺失值处理
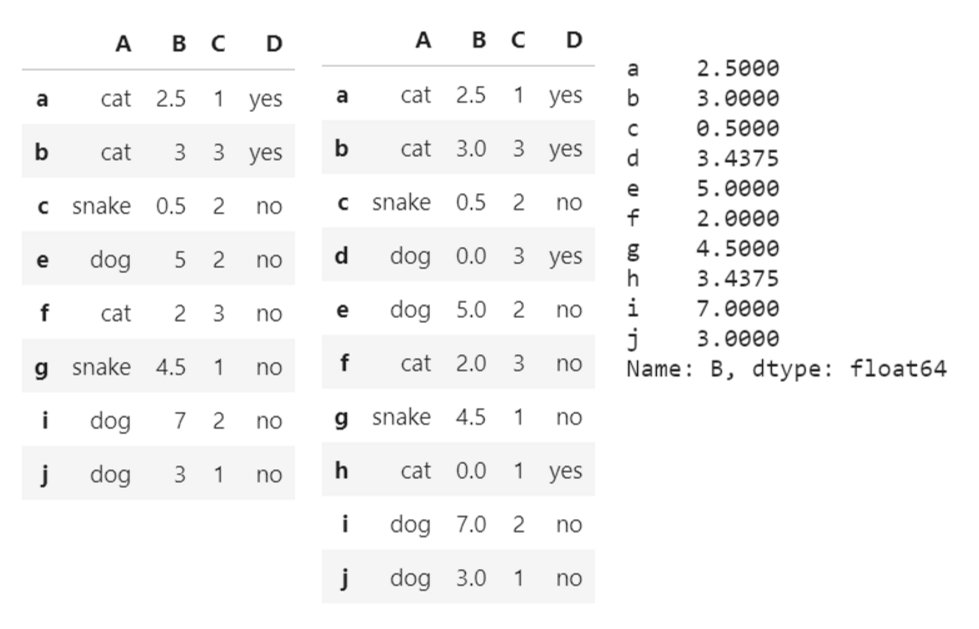
dropna(axis=, how=):丢弃 NaN 数据- axis:0 (按行丢弃),1 (按列丢弃)
- how:'any' (只要含有 NaN 数据就丢弃),'all' (所有数据都为 NaN 时丢弃)
fillna(value=):将 NaN 值都设置为 value 的值
df.dropna(how='any') # 删除数据表中含有空值的行
df.fillna(value=0) # 使用数字0填充数据表中空值
df['B'].fillna(df['B'].mean()) # 使用price均值对NA进行填充
输出
清理空格
df['city']=df['city'].map(str.strip) #清除city字段中的字符空格
大小写转换
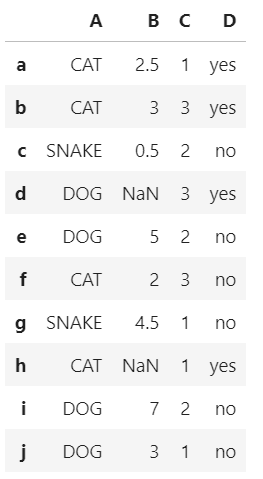
df['A'].str.upper() #city列大小写转换
输出
更改数据格式
df['C'].astype('int')
输出
a 1
b 3
c 2
d 3
e 2
f 3
g 1
h 1
i 2
j 1
Name: C, dtype: int32
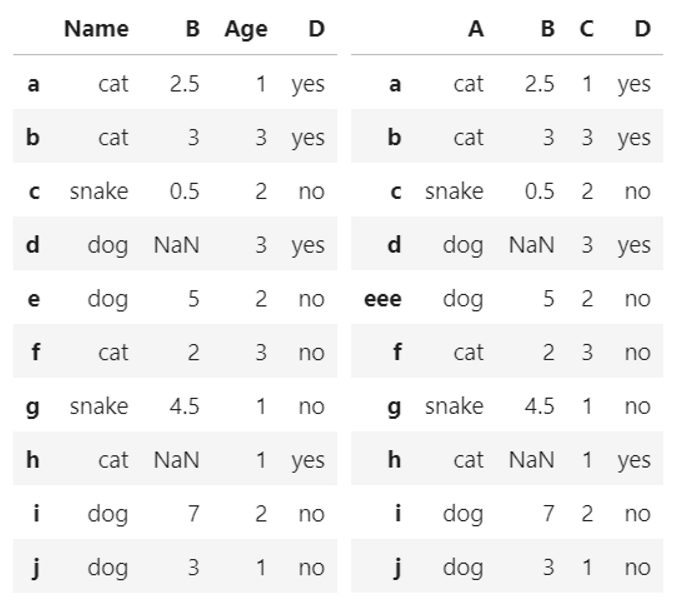
更改行列名称
df.rename(columns={'A': 'Name','C':'Age'}) #更改列名称
df.rename(index={'e': 'eee'}) #更改行名称
df.columns = ['animal','age','visits','priority'] #传入列表以改变列名称
df.index = [...] #传入列表以改变行名称
输出
重复值处理
df.duplicated() # 返回一个布尔型的Series,显示各行是否有重复行
df.duplicated().any() # 返回bool,查看是否有重复值
df.duplicated('k1') # 检查各行的k1列是否重复
df.duplicated(['k1','k2']) # 检查各行的k1,k2列是否重复
df.drop_duplicates() #保留第一个值,返回副本
df.drop_duplicates(keep='last') #保留最后一个值,返回副本
df.drop_duplicates(keep=False) #删除所有�重复值,返回副本
df.drop_duplicates('k1') #删除第一列重复值,返回副本
df.drop_duplicates(['k1','k2']) #删除全部列重复值,返回副本
df.drop_duplicates(inplace=True) #就地修改
数值修改及替换
df['D'].replace('yes', 'true')
输出
a true
b true
c no
d true
e no
f no
g no
h true
i no
j no
Name: D, dtype: object
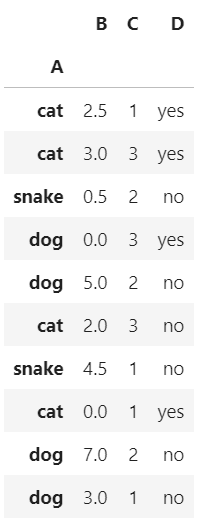
设置索引列
df_inner.set_index('A')
输出
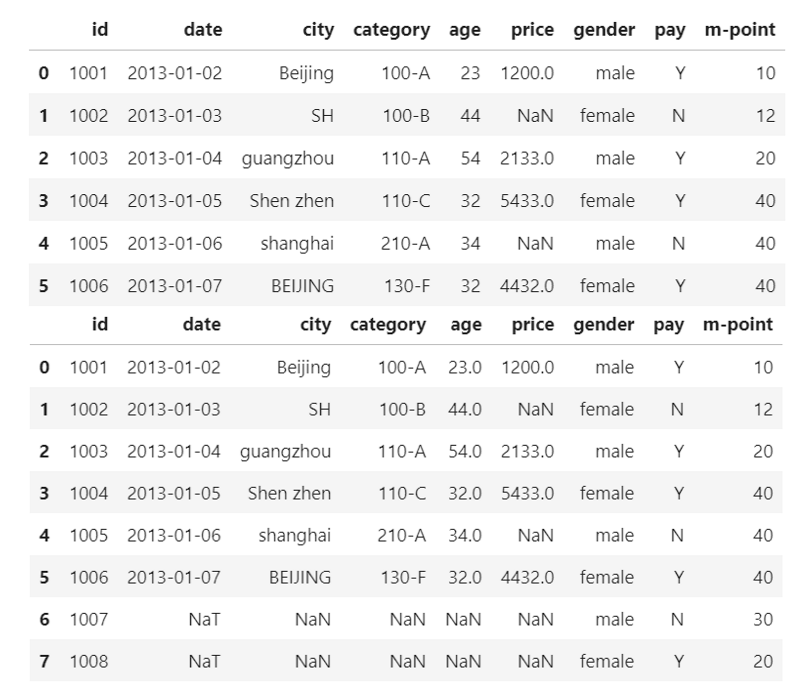
数据表合并
以下两张图为例
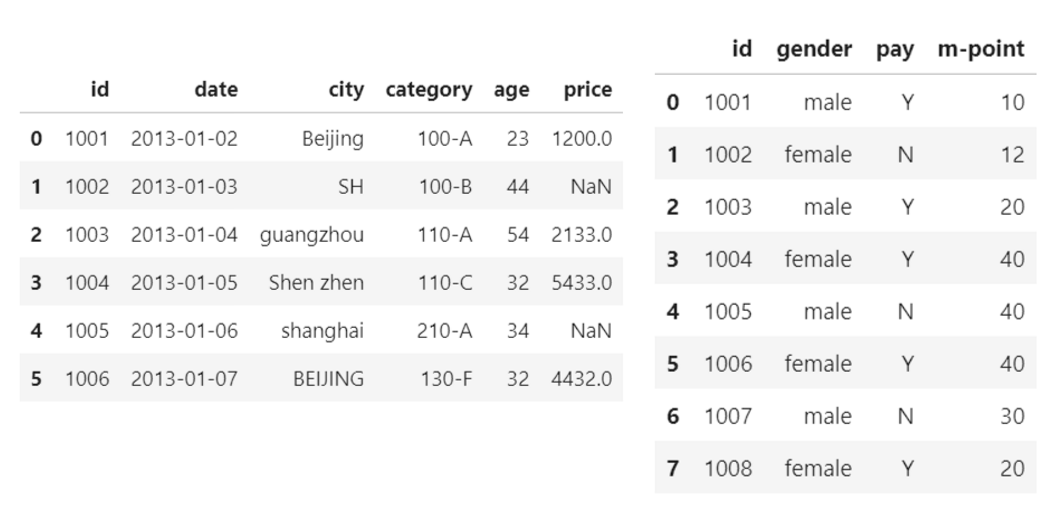
.merge()
参数
- on:列名,join 用来对齐的那一列的名字,用到这个参数的时候一定要保证左表和右表用来对齐的那一列都有相同的列名
- how:数据融合的方法
- sort:根据 dataframe 合并的 keys 按字典顺序排序,默认是,如果置 false 可以提高表现
df_inner=pd.merge(df1,df2,how='inner') #以小表为准
df_outer=pd.merge(df1,df2,how='outer') #以大表为准
df_left=pd.merge(df1,df2,how='left') #以左表为准,这里等同于inner_df
df_right=pd.merge(df1,df2,how='right') #以右表为准,这里等同于outer_df
输出
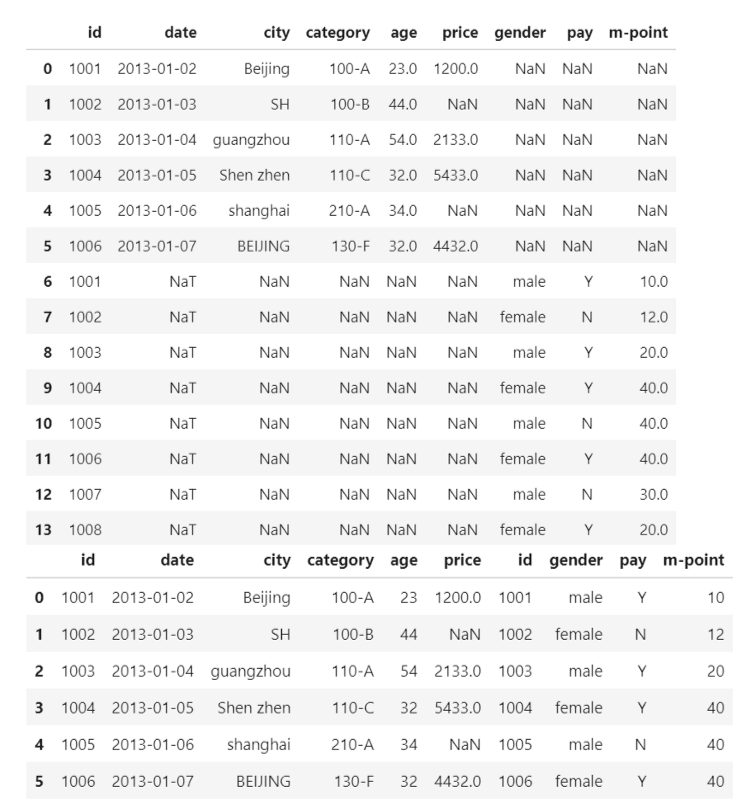
.concat()
第一个参数:需要合并的矩阵
axis:合并维度,0:按行合并,1:按列合并,默认为 0
join:处理非公有 列/行 的方式,inner:去除非公有的 列/行,outer:对非公有的 列/行 进行 NaN 值填充然后合并
ignore_index:是否重排行索引,若重排,行索引为顺序。默认为 0
pd.concat([df1, df2], join='outer', ignore_index=True) #按行合并,重排行索引
pd.concat([df1, df2], axis=1, join='inner') #按列合并
输出
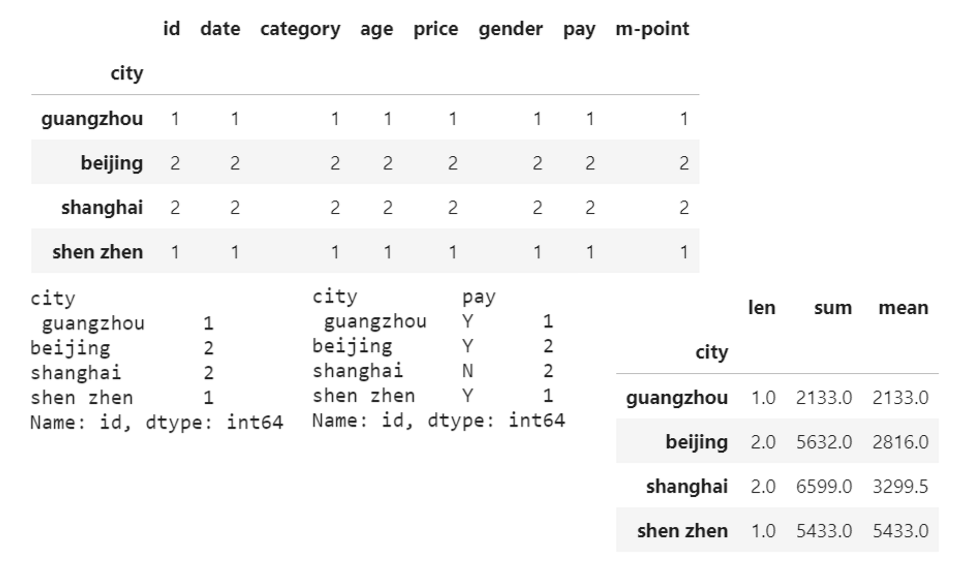
数据分组
分类汇总
df_inner.groupby('city').count() #对所有列进行计数汇总
df_inner.groupby('city')['id'].count() #对特定的ID列进行计数汇总
df_inner.groupby(['city','pay'])['id'].count() #对两个�字段进行汇总计数
df_inner.groupby('city')['price'].agg([len,np.sum, np.mean]) #对city字段进行汇总并计算price的合计和均值
输出
数据增删
更多:https://www.cnblogs.com/guxh/p/9420610.html
删除行列
df1.drop(['0','1']) #按行名删除(如果有的话)
df1.drop(df1.index[0:2]) #按行号删除
df.drop(['id','date'],axis=1) #按列名删除
df.drop(df.columns[0:2],axis=1) #按列号删除
del df['id'] #删除列(就地删除)
增加行

想增加一行,行名称为‘a’,内容为[16, 17, 18, 19]
df.loc['a'] = [16, 17, 18, 19]
df.at['a'] = [16, 17, 18, 19]
df.set_value('a', df.columns, [16, 17, 18, 19], takeable=False) # warning,set_value会被取消
df.loc[len(df)] = [16, 17, 18, 19]#简单地逐行添加内容
#.append()
s = pd.Series([16, 17, 18, 19], index=df.columns, name='5') #添加有name的Series
df.append(s) #赋值以生效
增加列
般涉及到增加列项时,经常会对现有的数据进行遍历运算,获得新增列项的值
#遍历DataFrame获取序列的方法
s = [a + c for a, c in zip(df['A'], df['C'])] # 通过遍历获取序列
s = [row['A'] + row['C'] for i, row in df.iterrows()] # 通过iterrows()获取序列,s为list
s = df.apply(lambda row: row['A'] + row['C'], axis=1) # 通过apply获取序列,s为Series
s = df['A'] + df['C'] # 通过Series矢量相加获取序列
s = df['A'].values + df['C'].values # 通过Numpy矢量相加获取序列
#通过df[]或者df.loc添加序列
df.loc[:, 'E'] = s
df['E'] = s
#.insert()可以指定插入位置,和插入列名称
df.insert(0, 'E', s) #在第0列插入s,命名为E
#.concat()
s = pd.Series([16, 17, 18, 19], name='E', index=df.index)
df = pd.concat([df, s], axis=1)
#简单地逐列添加内容
df[len(df)] = [16, 17, 18, 19]
数据运算
算术运算
- add(other)
data['A'].add(1)
- sub(other)
data['A'].sub(2)
逻辑运算
更多被运用到数据筛选中
符号
data["A"] > 2 # 返回Series
data[data["A"] > 2].head() # 返回DataFrame副本
data[(data["A"] > 1) & (data["A"] < 3)] # 多个逻辑判断
函数
- query(expr)
- expr:查询字符串
data.query("A<3 & A>1") # 返回DataFrame副本
- isin(values)
可以指定值进行一个判断,从而进行筛选操作
data[data["A"].isin([1, 2])] # 返回DataFrame副本
自定义运算
apply( func, axis=0 ):定义一个对列,最大值-最小值的函数
- func:自定义函数
- axis=0:默认是列,axis=1 为行进行运算
导入与导出
导入数据
- path:文件路径
- sep:分隔符,默认用","隔开
- usecols:指定读取的列名
可以使用 index_col=[0] 参数指定默认索引
pd.read_csv(filename) #从CSV文件导入数据
pd.read_table(filename) #从限定分隔符的文本文件导入数据
pd.read_excel(filename) #从Excel文件导入数据
pd.read_sql(query, connection_object) #从SQL表/库导入数据
pd.read_json(json_string) #从JSON格式的字符串导入数据
pd.read_html(url) #解析URL、字符串或者HTML文件,抽取其中的tables表格
pd.read_clipboard() #从你的粘贴板获取内容,并传给read_table()
导出数据
- path:文件路径
- sep:分隔符,默认用","隔开
- columns:选择需要的列索引
- header :boolean or list of string, default True,是否写入列索引
- index:是否写入行索引
- mode:'w':重写, 'a' 追加
df.to_csv(filename) #导出数据到CSV文件
df.to_excel(filename) #导出数据到Excel文件
df.to_sql(table_name, connection_object) #导出数据到SQL表
df.to_json(filename) #以Json格式导出数据到文本文件
转换成 json 格式通常用 df.to_json(filename, orient='records', force_ascii=False)
例
- 取出索引为 [3, 4, 8] 行的 animal 和 age 列
df.loc[df.index[[3, 4, 8]], ['animal', 'age']]
- 取出 age 值缺失的行
df[df['age'].isnull()]
- 计算每个不同种类 animal 的 age 的平均数
df.groupby('animal')['age'].mean()
- 计算 df 中每个种类 animal 的数量
df['animal'].value_counts()
- 将 priority 列中的 yes, no 替换为布尔值 True, False
df['priority'] = df['priority'].map({'yes': True, 'no': False})
- 求哪一列的和最小
df.sum().idxmin()
- 去除 Unnamed:0 列
pd.read_csv(path, index_col=0)
# or
pd.to_csv(path, index=False)
预览 DataFrame
一个独立的支持库,pandas_profiling,可以快速预览数据集。
import pandas_profiling as pp
pp.ProfileReport(df)
这个函数支持任意 DataFrame,并生成交互式 HTML 数据报告:
- 第一部分是纵览数据集,还会列出数据一些可能存在的问题;
- 第二部分汇总每列数据,点击 toggle details 查看更多信息;
- 第三部分显示列之间的关联热力图;
- 第四部分显示数据集的前几条数据。
profile.to_file("your_report.html")
保存 html 文件
profile = pp.ProfileReport(data)
profile.to_file("output_file.html")