索引
索引是存储引擎用于�提高数据库表的访问速度的一种数据结构,它为特定的 mysql 字段进行一些特定的算法排序,比如二叉树的算法和哈希算法
- 哈希算法是通过建立特征值,然后根据特征值来快速查找。
- 用的最多,并且是 mysql 默认的就是二叉树算法 BTREE(B+ 树),通过 BTREE 算法建立索引的字段,比如扫描 20 行就能得到未使用 BTREE 前扫描了 2^20^ 行的结果。
索引的使用场景
索引的优缺点
优点
- 加快数据查找的速度
- 为用来排序或分组的字段添加索引,可以加快分组和排序的速度
- 加快表与表之间的连接
缺点
- 建立索引需要占用物理空间
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长
什么情况下需要建索引
- 经常用于查询的字段
- 经常用于连接的字段建立索引,可以加快连接的速度
- 经常需要排序的字段建立索引,因为索引已经排好序,可以加快排序查询速度
什么情况下不建索引
where条件中用不到的字段不适合建立索引- 表记录较少。比如只有几百条数据,没必要加索引。
- 需要经常增删改。需要评估是否适合加索引
- 参与列计算的列不适合建索引
- 区分度不高的字段不适合建立索引,如性别,只有男/女/未知三个值。加了索引,查询效率也不会提高。
索引的数据结构
B+ 树索引
B+ 树是基于 B 树和叶子节点顺序访问指针进行实现,它具有 B 树的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ 树中,节点中的 key 从左到右递增排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
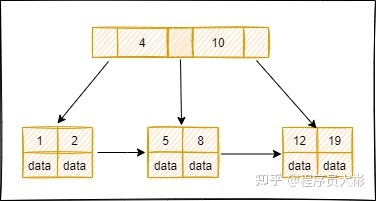
进行查找操作时,首先在根节点进行二分查找,找到 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的数据项。
MySQL 数据库使用最多的索引类型是 BTREE 索引,底层基于 B+ 树数据结构来实现。
mysql> show index from blog\G;
*************************** 1. row ***************************
Table: blog
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: blog_id
Collation: A
Cardinality: 4
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL
哈希索引
哈希索引是基于哈希表实现的,对于每一行数据,存储引擎会对索引列进行哈希计算得到哈希码,并且哈希算法要尽量保证不同的列值计算出的哈希码值是不同的
将哈希码的值作为哈希表的 key 值,将指向数据行的指针作为哈希表的 value 值。这样查找一个数据的时间复杂度就是 O(1),一般多用于精确查找。
Hash 索引和 B+ 树索引的区别?
- 哈希索引不支持排序,因为哈希表是无序的。
- 哈希索引不支持范围查找。
- 哈希索引不支持模糊查询及多列索引的最左前缀匹配。
- 因为哈希表中会存在哈希冲突,所以哈希索引的性能不稳定,而 B+ 树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。
为什么 B+ 树比 B 树更适合实 现数据库索引?
- 由于 B+ 树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可,
- 但是 B 树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫
- 所以 B+ 树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以通常 B+ 树用于数据库索引。
- B+ 树的节点只存储索引 key 值,具体信息的地址存在于叶子节点的地址中。这就使以页为单位的索引中可以存放更多的节点。减少更多的 I/O 支出。
- B+ 树的查询效率更加稳定,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
索引的类型
INDEX 普通索引
- 允许出现相同的索引内容。
UNIQUE KEY 唯一索引
- 唯一,允许出现空值
- 用途:唯一标识数据库表中的每条记录,主要是用来防止数据重复插入。
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE KEY(column_1,column_2,...);
PRIMARY KEY 主键索引
- 唯一,非空
组合索引
- 在表中的多个字段组合上创建的索引
- 只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时需遵循最左前缀原则。
fulltext index 全文索引
- 上述三种索引都是针对列的值发挥作用,但全文索引,可以针对值中的某个单词,比如一篇文章中的某个词
- 只能在
CHAR、VARCHAR和TEXT类型字段上使用全文索引 - 然而并没有什么卵用,因为只有 MYISAM 以及英文支持,并且效率让人不敢恭维
索引的设计原则
- 索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
- 话句话说,在维度高的列创建索引。
- 尽量使用短索引,因为较小的索引涉及到的磁盘 I/O 较少,查询速�度更快。
- 对于较长的字符串进行索引时应该指定一个较短的前缀长度(前缀索引)
- 索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
- 对 where, on, group by, order by 中频繁出现的列使用索引。
- 使用组合索引,可以减少文件索引大小,在使用时速度要优于多个单列索引。
- 利用最左前缀原则。
索引何时会失效
导致索引失效的情况:
- 条件中有
or- 例如
select * from table_name where a = 1 or b = 3
- 例如
- 在索引上进行计算会导致索引失效
- 例如
select * from table_name where a + 1 = 2
- 例如
- 在索引的类型上进行数据类型的隐式转换,会导致索引失效,
- 例如字符串一定要加引号,假设
select * from table_name where a = '1'会使用到索引,如果写成select * from table_name where a = 1则会导致索引失效。
- 例如字符串一定要加引号,假设
- 在索引中使用函数会导致索引失效
- 例如
select * from table_name where abs(a) = 1
- 例如
- 在使用 like 查询时以 % 开头会导致索引失效
- 索引上使用 !=、<> 进行判断时会导致索引失效
- 例如
select * from table_name where a != 1
- 例如
- 索引字段上使用 is null/is not null 判断时会导致索引失效
- 例如
select * from table_name where a is null
- 例如
索引的相关操作
索引的创建
ALTER TABLE
适用于表创建完毕之后再添加。
ALTER TABLE 表名 ADD 索引类型(unique,primary key,fulltext,index) 索引名 (字段名)
ALTER TABLE `table_name` ADD INDEX `index_name` (`column_list`) -- 索引名,可要可不要;如果不要,当前的索引名就是该字段名。
ALTER TABLE `table_name` ADD UNIQUE (`column_list`)
ALTER TABLE `table_name` ADD PRIMARY KEY (`column_list`)
ALTER TABLE `table_name` ADD FULLTEXT KEY (`column_list`)
CREATE INDEX
CREATE INDEX 可对表增加普通索引或 UNIQUE 索引。
--例:只能添加这两种索引
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
另外,还可以在建表时添加:
CREATE TABLE `test1` (
`id` smallint(5) UNSIGNED AUTO_INCREMENT NOT NULL, -- 注意,下面创建了主键索引,这里就不用创建了
`username` varchar(64) NOT NULL COMMENT '用户名',
`nickname` varchar(50) NOT NULL COMMENT '昵称/姓名',
`intro` text,
PRIMARY KEY (`id`),
UNIQUE KEY `unique1` (`username`), -- 索引名称,可要可不要,不要就是和列名一样
KEY `index1` (`nickname`),
FULLTEXT KEY `intro` (`intro`)
) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='后台用户表';
索引的删除
DROP INDEX `index_name` ON `talbe_name`
ALTER TABLE `table_name` DROP INDEX `index_name`
-- 这两句都是等价的,都是删除掉table_name中的索引index_name;
ALTER TABLE `table_name` DROP PRIMARY KEY -- 删除主键索引,注意主键索引只能用这种方式删除
索引的查看
show index from tablename;
索引的更改
更改个毛线,删掉重建一个既可
组合索引
ALTER TABLE `myIndex` ADD INDEX `name_city_age` (vc_Name(10),vc_City,i_Age);
上述的步骤就是将 vc_Name,vc_City,i_Age 建到一个索引里
这样一来,在执行这条 SQL 查询语句时:
SELECT `i_testID` FROM `myIndex` WHERE `vc_Name`='erquan' AND `vc_City`='郑州' AND `i_Age`=25; -- 关联搜索;
查询速度会比只建立某一个字段的单独索引要快得多
如果分别在 vc_Name,vc_City,i_Age 上建立单列索引,让该表有 3 个单列索引,查询的速度将远远低于组合索引。
虽然此时有了三个索引,但 MySQL 只能用到其中的那个它认为似乎是最有效率的单列索引,另外两个是用不到的,也就是说还是一个全表扫描的过程。
最左匹配原则
建立这样的组合索引,其实是相当于分别建立了:
vc_Name, vc_City, i_Agevc_Name, vc_Cityvc_Name
为什么没有 vc_City, i_Age 等这样的组合索引呢?这是因为 mysql 组合索引 “最左前缀” 的结果。简单的理解就是只从最左面的开始组合。并不是只要包含这三列的查询都会用到该组合索引,下面的几个 T-SQL 会用到:
SELECT * FROM myIndex WHREE vc_Name=”erquan” AND vc_City=”郑州”
SELECT * FROM myIndex WHREE vc_Name=”erquan”
而下面几个则不会用到:
SELECT * FROM myIndex WHREE i_Age=20 AND vc_City=”郑州”
SELECT * FROM myIndex WHREE vc_City=”郑州”
也就是,name_city_age(vc_Name(10),vc_City,i_Age) 会从左到右进行索引,如果没有左前索引,Mysql 不执行索引查询。
范围查询后停止匹配
如果 SQL 语句中用到了组合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个组合索引去进行匹配。
当遇到范围查询 (>、<、between、like) 后就会停止匹配,后面的字段不会用到索引。
例
- 对
(a,b,c)建立索引,查询条件使用 a/ab/abc 会走索引,使用 bc 不会走索引。 - 对
(a,b,c,d)建立索引,查询条件为a = 1 and b = 2 and c > 3 and d = 4,那么 a、b 和 c 三个字段能用到索引,而 d 无法使用索引。因为遇到了范围查询。
如下图,对 (a, b) 建立索引,a 在索引树中是全局有序的,而 b 是全局无序,局部有序(当 a 相等时,会根据 b 进行排序)。直接执行 b = 2 这种查询条件无法使用索引。
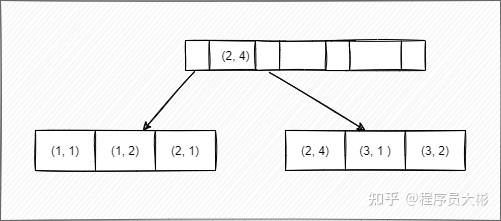
当 a 的值确定的时候,b 是有序的。例如 a = 1 时,b 值为 1,2 是有序的状态。当 a = 2 时候,b 的值为 1,4 也是有序状态。 当执行 a = 1 and b = 2 时 a 和 b 字段能用到索引。而执行 a > 1 and b = 2 时,a 字段能用到索引,b 字段用不到索引。因为 a 的值此时是一个范围,不是固定的,在这个范围内 b 值不是有序的,因此 b 字段无法使用索引。
例
例如建立索引 (a,b,c)
第一种
select * from table_name where a = 1 and b = 2 and c = 3
select * from table_name where b = 2 and a = 1 and c = 3
上面两次查询过程中所有值都用到了索引,⭐ where 后面字段调换不会影响查询结果,因为 MySQL 中的优化器会自动优化查询顺序。
第二种
select * from table_name where a = 1
select * from table_name where a = 1 and b = 2
select * from table_name where a = 1 and b = 2 and c = 3
答案是三个查询语句都用到了索引,因为三个语句都是从最左开始匹配的。
第三种
select * from table_name where b = 1
select * from table_name where b = 1 and c = 2
答案是这两个查询语句都没有用到索引,因为不是从最左边开始匹配的
第四种
select * from table_name where a = 1 and c = 2
这个查询语句只有 a 列用到了索引,c 列没有用到索引,因为中间跳过了 b 列,不是从最左开始连续匹配的。
第五种
select * from table_name where a = 1 and b < 3 and c < 1
这个查询中只有 a 列和 b 列使用到了索引,而 c 列没有使用索引,因为根据最左匹配查询原则,遇到范围查询会停止。
第六种
select * from table_name where a like 'ab%';
select * from table_name where a like '%ab'
select * from table_name where a like '%ab%'
对于列为字符串的情况,只有前缀匹配可以使用索引,中缀匹配和后缀匹配只能进行全表扫描。
聚集索引
InnoDB 使用表的主键构造主键索引树,同时叶子节点中存放的即为整张表的记录数据,这就是聚集索引 / 聚簇索引(Cluster Index)
聚集索引叶子节点的存储是逻辑上连续的,使用双向链表连接,叶子节点按照主键的顺序排序,因此对于主键的排序查找和范围查找速度比较快。
聚集索引的叶子节点就是整张表的行记录。InnoDB 主键使用的就是聚集索引。聚集索引要比非聚集索引查询效率高很多。
对于 InnoDB 来说,聚集索引一般是表中的主键索引
- 如果表中没有显式地指定主键,则会选择表中的第一个不允许为
NULL的唯一索引。 - 如果没有主键也没有合适的唯一索引,那么
InnoDB内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键长度为 6 个字节,它的值会随着数据的插入自增。
除了 Cluster Index 外的索引是 Secondary Index (辅助索引或二级索引)。辅助索引中的叶子节点保存的是主键。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。
换句话说,覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了, 而无需回表查询。
对于 innodb 表的二级索引,如果索引能覆盖到查询的列,那么就可以避免对主键索引的二次查询。
不是所有类型的索引都可以成为覆盖索引。覆盖索引要存储索引列的值,而哈希索引、全文索引不存储索引列的值,所以 MySQL 使用 b+ 树索引做覆盖索引。
语法
对于使用了覆盖索引的查询,在查询前面使用 explain,输出的 extra 列会显示为 using index。
比如 user_like 用户点赞表,组合索引为 (user_id, blog_id),user_id 和 blog_id 都不为 null。
explain select blog_id from user_like where user_id = 13;
explain 结果的 Extra 列为 Using index,查询的列被索引覆盖,并且 where 筛选条件符合最左前缀原则,通过索引查找(index seek)就能直接找到符合条件的数据,不需要回表查询数据。
explain select user_id from user_like where blog_id = 1;
explain 结果的 Extra 列为 Using where; Using index, 查询的列被索引覆盖,where 筛选条件不符合最左前缀原则,无法通过索引查找找到符合条件的数据,但可以通过索引扫描(index scan)找到符合条件的数据,也不需要回表查询数据。

前缀索引
前缀索引是指对文本或者字符串的前几个字符建立索引,这样索引的长度更短,查询速度更快。
如果索引列长度过长,这种列索引时将会产生很大的索引文件,不便于操作,可以使用前缀索引方式进行索引前缀索引应该控制在一个合适的点,控制在 0.31 黄金值即可(大于这个值就可以创建)。
SELECT COUNT(DISTINCT(LEFT(`title`,10)))/COUNT(*) FROM Arctic;
这个值大于 0.31 就可以创建前缀索引,Distinct 去重复
ALTER TABLE `user` ADD INDEX `uname`(title(10));
增加前缀索引 SQL,将人名的索引建立在 10,这样可以减少索引文件大小,加快索引查询速度。
建立前缀索引的方式:
# email列创建前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
强制索引
强制索引 MySQL FORCE INDEX
SELECT * FROM TABLE1 FORCE INDEX (FIELD1) …
以上的 SQL 语句只使用建立在 FIELD1 上的索引,而不使用其它字段上的索引。
忽略索引 IGNORE INDEX
SELECT * FROM TABLE1 IGNORE INDEX (FIELD1, FIELD2) …
在上面的 SQL 语句中,TABLE1 表中 FIELD1 和 FIELD2 上的索引不被使用。
关闭查询缓冲 SQL_NO_CACHE
SELECT SQL_NO_CACHE field1, field2 FROM TABLE1;
有一些 SQL 语句需要实时地查询数据,或者并不经常使用(可能一天就执行一两次),这样就需要把缓冲关了;不管这条 SQL 语句是否被执行过,服务器都不会在缓冲区中查找,每次都会执行它。
强制查询缓冲 SQL_CACHE
SELECT SQL_CALHE * FROM TABLE1;
如果在 my.ini 中的 query_cache_type 设成 2,这样只有在使用了 SQL_CACHE 后,才使用查询缓冲。
优先操作 HIGH_PRIORITY
HIGH_PRIORITY 可以使用在 select 和 insert 操作中,让 MySQL 知道,这个操作优先进行。
SELECT HIGH_PRIORITY * FROM TABLE1;
滞后操作 LOW_PRIORITY
LOW_PRIORITY 可以使用在 insert 和 update 操作中,让 MySQL 知道,这个操作滞后。
update LOW_PRIORITY table1 set field1= where field1= …
延时插入 INSERT DELAYED
INSERT DELAYED INTO table1 set field1= …
INSERT DELAYED INTO,是客户端提交数据给 MySQL,MySQL 返回 OK 状态给客户端。而此时并不是已经将数据插入表,而是存储在内存里面等待排队,当 MySQL 有空余时,再插入。
另一个重要的好处是,来自许多客户端的插入被集中在一起,并被编写入一个块。这比执行许多独立的插入要快很多。坏处是,不能返回自动递增的 ID,以及系统崩溃时,MySQL 还没有来得及插入数据的话,这些数据将会丢失。
强制连接顺序 STRAIGHT_JOIN
SELECT TABLE1.FIELD1, TABLE2.FIELD2 FROM TABLE1 STRAIGHT_JOIN TABLE2 WHERE …
由上面的 SQL 语句可知,通过 STRAIGHT_JOIN 强迫 MySQL 按 TABLE1、TABLE2 的顺序连接表。
如果你认为按自己的顺序比 MySQL 推荐的顺序进行连接的效率高的话,就可以通过 STRAIGHT_JOIN 来确定连接顺序。
强制使用临时表 SQL_BUFFER_RESULT
SELECT SQL_BUFFER_RESULT * FROM TABLE1 WHERE …
当我们查询的结果集中的数据比较多时,可以通过 SQL_BUFFER_RESULT 选项强制将结果集放到临时表中,这样就可以很快地释放 MySQL 的表锁(这样其它的 SQL 语句就可以对这些记录进行查询了),并且可以长时间地为客户端提供大记录集。
分组使用临时表 SQL_BIG_RESULT 和 SQL_SMALL_RESULT
SELECT SQL_BUFFER_RESULT FIELD1, COUNT(*) FROM TABLE1 GROUP BY FIELD1;
一般用于分组或 DISTINCT 关键字,这个选项通知 MySQL,如果有�必要,就将查询结果放到临时表中,甚至在临时表中进行排序。
SQL_SMALL_RESULT 比起 SQL_BIG_RESULT 差不多,很少使用。