OpenMP
介绍
OpenMP 是一种应用程序接口 (API),可用于显式地指示多线程、共享内存并行性。
它由三个主要的 API 组件组成:
- 编译器指令
- 运行时库函数
- 环境变量
它是 Open Multi-Processing 的缩写,是一个应用程序接口(API),可用于显式指导多线程、共享内存的并行性。
在项目程序已经完成好的情况下不需要大幅度的修改源代码,只需要加上专用的 pragma 来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同��步互斥以及通信。
当选择忽略这些 pragma,或者编译器不支持 OpenMp 时,程序又可退化为通常的程序 (一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP 提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据分集的多线程程序设计,OpenMP 是一个很好的选择。
共享内存模型
OpenMP 是为多处理器或多核共享内存机器设计的。底层架构可以是共享内存 UMA 或 NUMA。即 (Uniform Memory Access 和 Non-Uniform Memory Access)
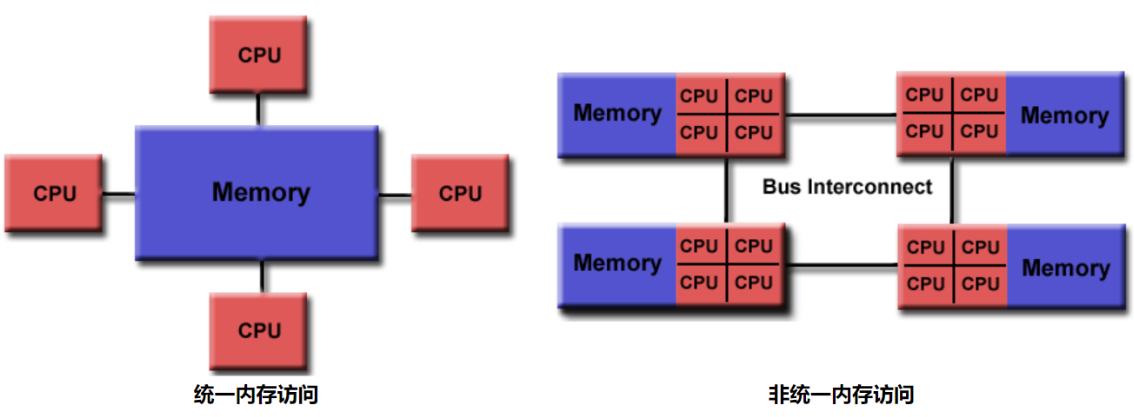
因为 OpenMP 是为共享内存并行编程而设计的,所以它在很大程度上局限于单节点并行性。通常,节点上处理元素 (核心) 的数量决定了可以实现多少并行性。
基于线程的并行性
OpenMP 程序仅通过使用线程来实现并行性。
执行线程是操作系统可以调度的最小处理单元。一种可以自动运行的子程序,这个概念可能有助于解释什么是线程。
线程存在于单个进程的资源中。没有这个进程,它们就不复存在。
通常,线程的数量与机器处理器/核心的数量相匹配。但是,线程的实际��使用取决于应用程序。
Fork - Join 模型
OpenMP 使用并行执行的 fork-join 模型:
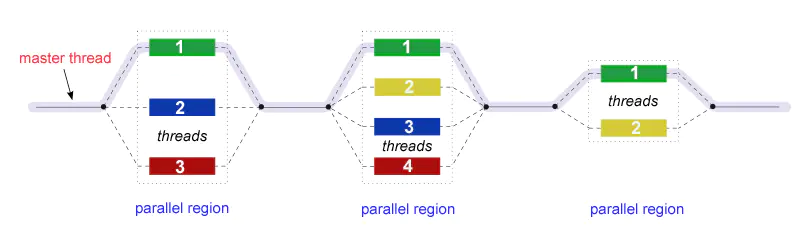
所有 OpenMP 程序都开始于一个主线程。主线程按顺序执行,直到遇到第一个并行区域结构。
FORK:主线程然后创建一组并行线程。
之后程序中由并行区域结构封装的语句在各个团队线程中并行执行。
JOIN:当团队线程完成并行区域结构中的语句时,它们将进行同步并终止,只留下主线程。
并行区域的数量和组成它们的线程是任意的。
数据范围
因为 OpenMP 是共享内存编程模型,所以在默认情况下,并行区域中的大多数数据都是共享的。
一个并行区域中的所有线程都可以同时访问共享数据。
OpenMP 为程序员提供了一种方法,可以在不需要默认共享范围的情况下显式地指定数据的“作用域”。
数据范围属性子句将更详细地讨论这个主题。
I/O
OpenMP 没有指定任何关于并行 I/O 的内容。如果多个线程试图从同一个文件进行写/读操作,这一点尤其重要。
如果每个线程都对不同的文件执行 I/O,那么问题就不那么重要了。
��完全由程序员来确保在多线程程序的上下文中正确地执行 I/O。
内存模型:经常刷新?
OpenMP 提供了线程内存的“宽松一致性”和“临时”视图 (用他们的话说)。换句话说,线程可以“缓存”它们的数据,
并且不需要始终与实际内存保持精确的一致性。
当所有线程以相同的方式查看共享变量非常重要时,程序员负责确保所有线程根据需要刷新该变量。
使用
在所有的预处理指令中,#pragma 指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作
#pragma omp parallel
omp 表示这个指令是 OpenMP 的指令,事实上所有 OpenMP 的指令都带有 omp 关键字
产生了 n 个线程执行之后的语句(n 为 CPU 核数)
循环并行
#pragma omp parallel for
把 for 循环中的任务等分成 n 份,分别由 n 个进程各执行一份
不能保证执行的先后顺序,如:
#include <iostream>
using namespace std;
int main()
{
#pragma omp parallel for
for (int i=0; i<10; i++)
{
cout << i;
}
return 0;
}
// output might be: 3068417952
循环并行化的条件
尽管 OpenMP 可以方便地对 for 循环进行并行化,但并不是所有的 for 循环都可以进行并行化。以下几种情况不能进行并行化:
- for 循环中的循环变量必须是有符号整形。例如,
for(unsigned int i = 0; i < 10; ++i){}会编译不通过; - for 循环中比较操作符必须是
<, <=, >, >=。例如for (int i = 0; i != 10; ++i){}会编译不通过; - for 循环中的第三个表达式,必须是整数的加减,并且加减的值必须是一个循环不变量。例如
for(int i = 0; i != 10; i = i + 1){}会编译不通过;感觉只能 ++i; i++; --i; 或 i--; - 如果 for 循环中的比较操作为 < 或 <=,那么循环变量只能增加;反之亦然。例如
for(int i = 0; i != 10; --i)会编译不通过; - 循环必须是单入口、单出口,也就是说循环内部不允许能够达到循环以外的跳转语句,exit 除外。异常的处理也必须在循环体内处理。例如:若循环体内的 break 或 goto 会跳转到循环体外,那么会编译不通过。
控制线程数
#pragma omp parallel num_threads(5)
或者
omp_set_num_threads(5);
#pragma omp parallel
对任务执行的细粒度控制
int main( )
{
#pragma omp parallel
{
cout << "All threads run this\n";
#pragma omp sections
{
#pragma omp section
{
cout << "This executes in parallel\n";
}
#pragma omp section
{
cout << "Sequential statement 1\n";
cout << "This always executes after statement 1\n";
}
#pragma omp section
{
cout << "This also executes in parallel\n";
}
}
}
}
所有线程并行运行在 pragma omp sections 之前但在 pragma omp parallel 之后的代码。 pragma omp section 则被分配出去,只运行一次。
tintin$ ./a.out
All threads run this
All threads run this
All threads run this
All threads run this
All threads run this
All threads run this
All threads run this
All threads run this
This executes in parallel
Sequential statement 1
This also executes in parallel
This always executes after statement 1
私有变量
#pragma parallel for private(i)
将循环变量 i 视为线程本地存储,每个线程都有该变量的副本
使用与主线程不同步的线程局部变量
#include <stdio.h>
#include <omp.h>
int main()
{
int idx = 100;
#pragma omp parallel private(idx)
{
printf("In thread %d idx = %d\n", omp_get_thread_num(), idx);
}
}
输出可能是
In thread 1 idx = 1
In thread 5 idx = 1
In thread 6 idx = 1
In thread 0 idx = 0
In thread 4 idx = 1
In thread 7 idx = 1
In thread 2 idx = 1
In thread 3 idx = 1
一些 API 函数
// 设置并行线程数
omp_set_num_threads(int _Num_threads);
// 获取当前并行线程数
omp_get_num_threads(void);
// 获取当前系统最大可并行运行的线程数
omp_get_max_threads(void);
// 获取当前运行线程的ID,注意和操作系统中的线程ID不同
omp_get_thread_num(void);
// 获取当前系统中处理器数目
omp_get_num_procs(void);
例
合并排序
#include <iostream>
#include <vector>
#include <omp.h>
using namespace std;
// g++ -fopenmp merge_sort.cpp -o merge_sort.o
vector<long> merge(const vector<long> &l, const vector<long> &r)
// 两个数组升序合并
{
vector<long> res;
int i = 0, j = 0;
while (i < l.size() && j < r.size())
{
if (l[i] < r[j])
res.push_back(l[i++]);
else
res.push_back(r[j++]);
}
// 添加某一数组的剩余部分
while (i < l.size())
res.push_back(l[i++]);
while (j < r.size())
res.push_back(r[j++]);
return res;
}
vector<long> mergeSortParallel(vector<long> &num, int threadNum)
// 归并排序 并行执行
{
if (num.size() == 1)
return num;
std::vector<long>::iterator middle = num.begin() + (num.size() / 2);
vector<long> l(num.begin(), middle);
vector<long> r(middle, num.end());
if (threadNum > 1)
{
#pragma omp parallel sections // 设置并行区域
{
#pragma omp section // 需要分配线程并行处理的区域
{
l = mergeSortParallel(l, threadNum / 2); // 分配一半线程执行此递归程序
}
#pragma omp section
{
r = mergeSortParallel(r, threadNum - threadNum / 2); // 分配剩余线程
}
}
}
else // 没有空闲的线程 由当前线程接管之后的递归程序
{
l = mergeSortParallel(l, 1);
r = mergeSortParallel(r, 1);
}
return merge(l, r);
}
vector<long> mergeSortSerial(vector<long> &num)
// 归并排序 线性执行
{
if (num.size() == 1)
return num;
std::vector<long>::iterator middle = num.begin() + (num.size() / 2);
vector<long> l(num.begin(), middle);
vector<long> r(middle, num.end());
l = mergeSortSerial(l);
r = mergeSortSerial(r);
return merge(l, r);
}
int main()
{
double start, end;
double parallelDuration, serialDuration;
cout << "总共有" << omp_get_max_threads() << "个线程" << endl;
vector<long> a(50000000), b(50000000);
for (long i = 0; i < 50000000; ++i)
{
int randInt = rand() % 10;
a[i] = randInt;
b[i] = randInt;
}
start = omp_get_wtime();
b = mergeSortSerial(b);
end = omp_get_wtime();
serialDuration = end - start;
cout << "串行计算共耗时" << serialDuration << "s." << endl;
start = omp_get_wtime();
a = mergeSortParallel(a, omp_get_max_threads());
end = omp_get_wtime();
parallelDuration = end - start;
cout << "并行计算共耗时" << parallelDuration << "s." << endl;
cout << "运行加速比为" << serialDuration / parallelDuration << endl;
}
使用八个线程运行此 merge sort 我的运行时执行时间为 2.1 秒,而使用一个线程则为 3.7 秒。 这里唯一需要记住的是,您需要注意线程数。 我从八个线程入手:里程可能会因您的系统配置而异。 但是,如果没有显式的线程数,最终将创建数百个(甚至数千个)线程,并且系统性能下降的可能性非常高。 同样,前面讨论的杂注 sections 已与 merge sort 代码很好地结合使用。