Go 进阶

一些总结
-
哪些种类型的值可以有间接底层部分?
在 Go 中,下列种类的类型的值可以有间接底层部分:
- 字符串类型 string
- 函数类型 func
- 切片类型 slice
- 映射类型 map
- 通道类型 channel
- 接口类型 interface
注意:此答案基于标准编译器的实现。事实上,函数类型的值是否有间接底层部分是难以证明的。 另外,字符串和接口类型的值在逻辑上应该被认为是不含间接底层部分。
-
哪些种类型的值可以用做内置
len(以及cap、close、delete和make)函数调用的实参?len cap close delete make string 可以 array / array ptr 可以 可以 slice 可以 可以 可以 map 可以 可以 可以 chan 可以 可以 可以 可以 可以被用做内置函数
len调用的参数的值的类型都可以被称为(广义上的)容器类型。 这些容器类型的值都可以跟在for-range循环的range关键字后。 -
各种容器类型比较
类型 容器值是否支持添加新的元素? 容器值中的元素是否可以被替换? 容器值中的元素是否可寻址? 访问容器值元素是否会更改容器长度? 容器值是否可以有间接底层部分? 字符串 string 否 否 否 否 是 (1) 数组 array 否 是 (2) 是 (2) 否 否 切片 slice 否 (3) 是 是 否 是 映射 map 是 是 否 否 是 通道 channel 是 (4) 否 否 是 是 (1) 对于标准编译器和运行时来说。
(2) 对于可寻址的数组值来说。
(3) 一般说来,一个切片的长度只能通过将另外一个切片赋值给它来被整体替换修改,这里我们不视这种情况为“添加新的元素”。 其实,切片的长度也可以通过调用
reflect.SetLen来单独修改。增加切片的长度可以看作是一种变相的向切片添加元素。 但reflect.SetLen函数的效率很低,因此很少使用。(4) 对于带缓冲并且缓冲未满的通道来说。
哪些种类型的值可以用组合字面量(T{...})表示?
下面在四种类型的值(除了切片和映射类型的零值)可以用组合字面量表示。
类型(T) | T{}是类型T的零值? |
|---|---|
| 结构体类型 | 是 |
| 数组类型 | 是 |
| 切片类型 | 否 (零值用nil表示) |
| 映射类型 | 否 (零值用nil表示) |
各种类型的尺寸
详见值复制成本一文。
哪些种类型的零值使用预声明的 nil 标识符表示?
下面这些类型的零值可以用预声明的 nil 标识符表示。
类型(T) | T(nil)的尺寸 |
|---|---|
| 指针 | 1 word |
| 切片 | 3 words |
| 映射 | 1 word |
| 通道 | 1 word |
| 函数 | 1 word |
| 接口 | 2 words |
上表列出的尺寸为标准编译器的结果。 一个 word(原生字)在 32 位的架构中为 4 个字节,在 64 位的架构中为 8 个字节。 一个 Go 值的间接底层部分未统计在尺寸中。
一个类型的零值的尺寸和其它非零值的尺寸是一致的。
我们可以为什么样的类型声明方法?
详见方法一文。
什么样的类型可以被内嵌在结构体类型中?
详见类型内嵌一文。
哪些函数调用将在编译时刻被估值?
如果一个函数调用在编译时刻被估值,则估值结果为一个常量。
| 函数 | 返回类型 | 其调用是否总是在编译时刻估值? |
|---|---|---|
| unsafe.Sizeof | uintptr | 是 |
| unsafe.Alignof | ||
| unsafe.Offsetof | ||
| len | int | 否 Go语言白皮书中提到:如果表达式s表示一个字符串常量,则表达式len(s)将在编译时刻估值;如果表达式s表示一个数组或者数组的指针,并且s中不含有数据接收操作和估值结果为非常量的函数调用,则表达式len(s)和cap(s)将在编译时刻估值。 |
| cap | ||
| real | 默认类型为 float64 (结果为类型不确定值) | 否 Go语言白皮书提到: 表达式real(s)和imag(s)在s为一个复数常量表达式时才在编译时刻估值。 |
| imag | ||
| complex | 默认类型为 complex128 (结果为类型不确定值) | 否 Go语言白皮书提到: 表达式complex(sr, si)只有在sr和si都为常量表达式的时候才在编译时刻估值。 |
哪些值是可寻址的?
请阅读此条问答获取详情。
哪些类型不支持比较?
请阅读此条问答获取详情。
哪些代码元素允许被声明却不使用?
| 允许被声明却不使用? | |
|---|---|
| 包引入 | 不允许 |
| 类型 | 允许 |
| 变量 | 包级全局变量允许,但局部变量不允许(对于官方标准编译器)。 |
| 常量 | 允许 |
| 函数 | 允许 |
| 跳转标签 | 不允许 |
哪些有名代码元素可多个被一起声明在一对小括号()中?
下面这些同种类的代码元素可多个被一起声明在一对小括号()中:
- 包引入
- 类型
- 变量
- 常量
函数是不能多个被一起声明在一对小括号()中的。跳转标签也不能。
哪些代码元素的声明可以被声明在函数内也可以被声明在函数外?
下面这些代码元素的声明既可以被声明在函数内也可以被声明在函数外:
- 类型
- 变量
- 常量
包引入必须被声明在其它种类的代码元素的声明之前。
函数必须声明在任何函数体之外。匿名函数可以定义在函数体内,但那不属于声明。
跳转标签必须声明在函数体内。
哪些表达式的估值结果可以包含一个额外的可选的值?
下列表达式的估值结果可以包含一个额外的可选的值:
| 语法 | 额外的可选的值(语法示例中的ok)的含义 | 舍弃额外的可选的值会对估值行为发生影响吗? | |
|---|---|---|---|
| 映射元素访问 | e, ok = aMap[key] | 键值key对应的条目是否存储在映射值中 | 否 |
| 数据接收 | e, ok = <- aChannel | 被接收到的值e是否是在通道关闭之前发送的 | 否 |
| 类型断言 | v, ok = anInterface.(T) | 接口值的动态类型是否为类型T | 是 (当可选的值被舍弃并且断言失败的时候,将产生一个恐慌。) |
几种导致当前协程永久阻塞的方法
无需引入任何包,我们可以使用下面几种方法使当前协程永久阻塞:
-
向一个永不会被接收数据的通道发送数据。
make(chan struct{}) <- struct{}{}
// 或者
make(chan<- struct{}) <- struct{}{} -
从一个未被并且将来也不会被发送数据的(并且保证永不会被关闭的)通道读取数据。
<-make(chan struct{})
// 或者
<-make(<-chan struct{})
// 或者
for range make(<-chan struct{}) {} -
从一个 nil 通道读取或者发送数据。
chan struct{}(nil) <- struct{}{}
// 或者
<-chan struct{}(nil)
// 或者
for range chan struct{}(nil) {} -
使用一个不含任何分支的
select流程控制代码块。select{}
几种衔接字符串的方法
详见字符串一文。
官方标准编译器中实现的一些优化
在Go程序运行中将会产生恐慌或者崩溃的情形
内存对齐
引入
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
在开始之前,希望你计算一下 Part1 共占用的大小是多少呢?
func main() {
fmt.Printf("bool size: %d\n", unsafe.Sizeof(bool(true)))
fmt.Printf("int32 size: %d\n", unsafe.Sizeof(int32(0)))
fmt.Printf("int8 size: %d\n", unsafe.Sizeof(int8(0)))
fmt.Printf("int64 size: %d\n", unsafe.Sizeof(int64(0)))
fmt.Printf("byte size: %d\n", unsafe.Sizeof(byte(0)))
fmt.Printf("string size: %d\n", unsafe.Sizeof("EDDYCJY"))
}
输出结果:
bool size: 1
int32 size: 4
int8 size: 1
int64 size: 8
byte size: 1
string size: 16
这么一算,Part1 这一个结构体的占用内存大小为 1+4+1+8+1 = 15 个字节。相信有的小伙伴是这么算的,看上去也没什么毛病
真实情况是怎么样的呢?我们实际调用看看,如下:
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
func main() {
part1 := Part1{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
}
输出结果:
part1 size: 32, align: 8
最终输出为占用 32 个字节。这与前面所预期的结果完全不一样。
在这里要提到 “内存对齐” 这一概念,才能够用正确的姿势去计算。
定义
有的小伙伴可能会认为内存读取,就是一个简单的字节数组摆放

上图表示一个坑一个萝卜的内存读取方式。但实际上 CPU 并不会以一个一个字节去读取和写入内存。
相反 CPU 读取内存是一块一块读取的,块的大小可以为 2、4、6、8、16 字节等大小。
块大小我们称其为内存访问粒度。如下图:
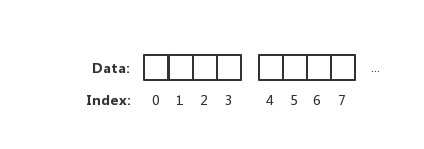
在样例中,假设访问粒度为 4。 CPU 是以每 4 个字节大小的访问粒度去读取和写入内存的。这才是正确的姿势
例
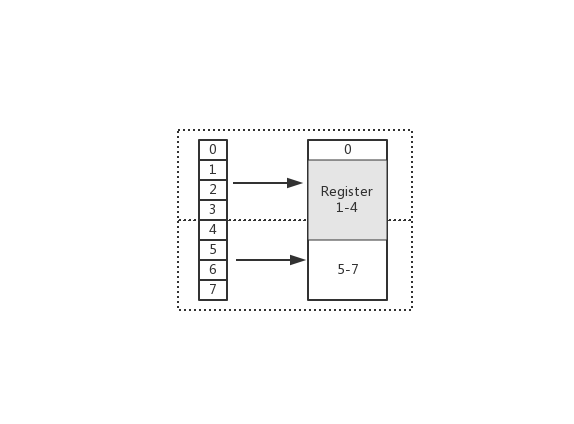
在上图中,假设从 Index1 开始读取,将会出现很崩溃的问题。因为它的内存访问边界是不对齐的。因此 CPU 会做一些额外的处理工作。如下:
- CPU 首次读取未对齐地址的第一个内存块,读取 0-3 字节。并移除不需要的字节 0
- CPU 再次读取未对齐地址的第二个内存块,读取 4-7 字节。并移除不需要的字节 5、6、7 字节
- 合并 1-4 字节的数据
- 合并后放入寄存器
从上述流程可得出,不做 “内存对齐” 是一件有点 "麻烦" 的事。因为它会增加许多耗费时间的动作。
而假设做��了内存对齐,从 Index0 开始读取 4 个字节,只需要读取一次,也不需要额外的运算。这显然高效很多,是标准的空间换时间做法。
为什么要关心对齐
- 你正在编写的代码在性能(CPU、Memory)方面有一定的要求
- 你正在处理向量方面的指令
- 某些硬件平台(ARM)体系不支持未对齐的内存访问
另外作为一个工程师,你也很有必要学习这块知识点哦 :)
为什么要做对齐
- 平台(移植性)原因:不是所有的硬件平台都能够访问任意地址上的任意数据。例如:特定的硬件平台只允许在特定地址获取特定类型的数据,否则会导致异常情况
- 性能原因:若访问未对齐的内存,将会导致 CPU 进行两次内存访问,并且要花费额外的时钟周期来处理对齐及运算。而本身就对齐的内存仅需要一次访问就可以完成读取动作
默认系数
在不同平台上的编译器都有自己默认的 “对齐系数”,可通过预编译命令 #pragma pack(n) 进行变更,n 就是代指 “对齐系数”。一般来讲,我们常用的平台的系数如下:
- 32 位:4
- 64 位:8
另外要注意,不同硬件平台�占用的大小和对齐值都可能是不一样的。因此本文的值不是唯一的,调试的时候需按本机的实际情况考虑
类型的对称系数
在 Go 中可以调用 unsafe.Alignof 来返回相应类型的对齐系数。
func main() {
fmt.Printf("bool align: %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("int32 align: %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("int8 align: %d\n", unsafe.Alignof(int8(0)))
fmt.Printf("int64 align: %d\n", unsafe.Alignof(int64(0)))
fmt.Printf("byte align: %d\n", unsafe.Alignof(byte(0)))
fmt.Printf("string align: %d\n", unsafe.Alignof("EDDYCJY"))
fmt.Printf("map align: %d\n", unsafe.Alignof(map[string]string{}))
}
bool align: 1
int32 align: 4
int8 align: 1
int64 align: 8
byte align: 1
string align: 8
map align: 8
通过观察输出结果,可得知基本都是 2^n,最大也不会超过 8。这是因为当前测试(64 位)编译器默认对齐系数是 8,因此最大值不会超过这个数
结构体的整体对齐
在上小节中,提到了结构体中的成员变量要做字节对齐。那么想当然身为最终结果的结构体,也是需要做字节对齐的
对齐规则
- 结构体的成员变量,第一个成员变量的偏移量为 0。往后的每个成员变量的对齐值必须为编译器默认对齐长度(
#pragma pack(n))或当前成员变量类型的长度(unsafe.Sizeof),取最小值作为当前类型的对齐值,其偏移量必须为对齐值的整数倍 - 结构体本身,对齐值必须为编译器默认对齐长度(
#pragma pack(n))或结构体的所有成员变量类型中的最大长度,取�最大数的最小整数倍作为对齐值 - 结合以上两点,可得知若编译器默认对齐长度(
#pragma pack(n))超过结构体内成员变量的类型最大长度时,默认对齐长度是没有任何意义的
分析流程
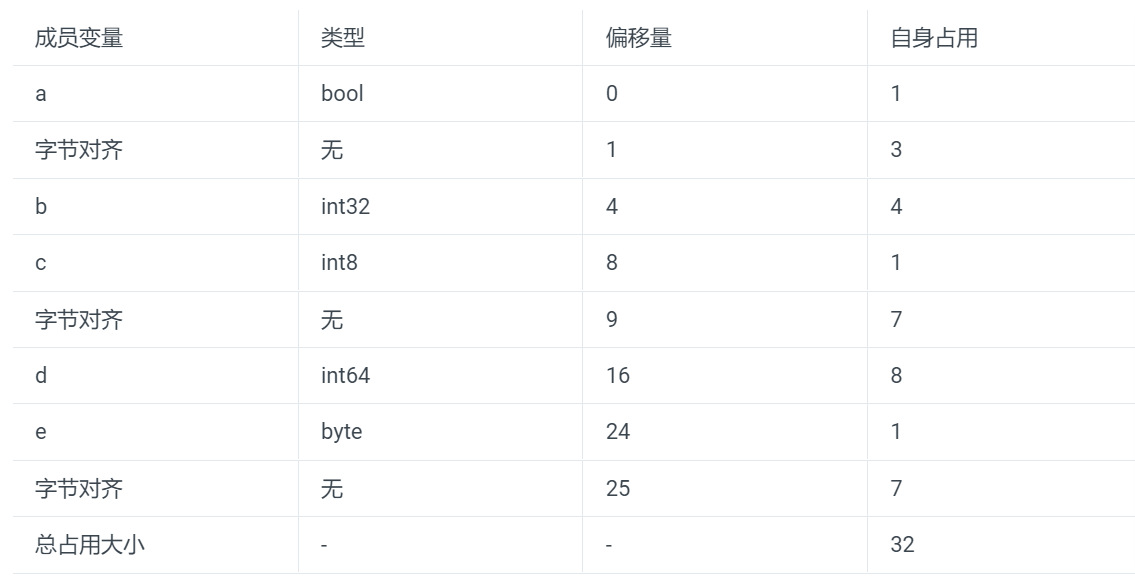
变量对齐
-
第一个成员 a
-
类型为 bool
-
大小/对齐值为 1 字节
-
初始地址,偏移量为 0。占用了第 1 位
-
-
第二个成员 b
-
类型为 int32
-
大小 / 对齐值为 4 字节
-
根据规则 1,其偏移量必须为 4 的整数倍。确定偏移量为 4,因此 2-4 位为 Padding。而当前数值从第 5 位开始填充,到第 8 位。如下:axxx|bbbb
-
-
第三个成员 c
-
类型为 int8
-
大小/对齐值为 1 字节
-
根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 8。不需要额外对齐,填充 1 个字节到第 9 位。如下:axxx|bbbb|c...
-
-
第四个成员 d
-
类型为 int64
-
大小/对齐值为 8 字节
-
根据规则 1,其偏移量必须为 8 的整数倍。确定偏移量为 16,因此
9-16 位为 Padding。而当前数值从第 17 位开始写入,到第 24 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd
-
-
第五个成员 e
-
类型为 byte
-
大小/对齐值为 1 字节
-
根据规则 1,其偏移量必须为 1 的整数倍。当前偏移量为 24。不需要额外对齐,填充 1 个字节到第 25 位。如下:axxx|bbbb|cxxx|xxxx|dddd|dddd|e...
-
整体对齐
在每个成员变量进行对齐后,根据规则 2,整个结构体本身也要进行字节对齐,因为可发现它可能并不是 2^n,不是偶数倍。显然不符合对齐的规则
根据规则 2,可得出对齐值为 8。现在的偏移量为 25,不是 8 的整倍数。因此确定偏移量为 32。对结构体进行对齐
axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
调整字段顺序来优化内存
在上一小节,可得知根据成员变量的类型不同,其结构体的内存会产生对齐等动作。那假设字段顺序不同,会不会有什么变化呢?我们一起来试试吧 :-)
type Part1 struct {
a bool
b int32
c int8
d int64
e byte
}
type Part2 struct {
e byte
c int8
a bool
b int32
d int64
}
func main() {
part1 := Part1{}
part2 := Part2{}
fmt.Printf("part1 size: %d, align: %d\n", unsafe.Sizeof(part1), unsafe.Alignof(part1))
fmt.Printf("part2 size: %d, align: %d\n", unsafe.Sizeof(part2), unsafe.Alignof(part2))
}
part1 size: 32, align: 8
part2 size: 16, align: 8
通过结果可以惊喜的发现,只是 “简单” 对成员变量的字段顺序进行改变,就改变了结构体占用大小
Part1 内存布局:axxx|bbbb|cxxx|xxxx|dddd|dddd|exxx|xxxx
Part2 内存布局:ecax|bbbb|dddd|dddd
通过调整结构体内成员变量的字段顺序可以达到缩小结构体占用大小的的效果,因为它巧妙地减少了 Padding 的存在,让它们更 “紧凑” 了。这一点对于加深 Go 的内存布局印象和大对象的优化非常有帮助。
边界检查消除
Go 是一个内存安全的语言。在数组和切片的索引和子切片操作中,Go 运行时将检查操作中使用的下标是否越界。 如果下标越界,一个恐慌将产生,以防止这样的操作破坏内存安全。这样的检查称为边界检查。
边界检查使得我们的代码能够安全地运行;但是另一方面,也使得我们的代码运行效率略微降低。
从 Go 官方工具链 1.7 开始,官方标准编译器使用了一个新的基于 SSA(single-assignment form,静态单赋值形式)的后端。 SSA 使得 Go 编译器可以有效利用诸如 BCE(bounds check elimination,边界检查消除)和 CSE(common subexpression elimination,公共子表达式消除)等优化:
- BCE 可以避免很多不必要的边界检查
- CSE 可以避免很多重复表达式的计算,从而使得编译器编译出的程序执行效率更高。
有时候这些优化的效果非常明显。
本文将展示一些例子来解释边界检查消除在官方标准编译器 1.7+ 中的表现。
对于 Go 官方工具链 1.7+,我们可以使用编译器选项 -gcflags="-d=ssa/check_bce/debug=1" 来列出哪些代码行仍然需要边界检查。
例子 1
// example1.go
package main
func f1(s []int) {
_ = s[0] // 第5行: 需要边界检查
_ = s[1] // 第6行: 需要边界检查
_ = s[2] // 第7行: 需要边界检查
}
func f2(s []int) {
_ = s[2] // 第11行: 需要边界检查
_ = s[1] // 第12行: 边界检查消除了!
_ = s[0] // 第13行: 边界检查消除了!
}
func f3(s []int, index int) {
_ = s[index] // 第17行: 需要边界检查
_ = s[index] // 第18行: 边界检查消除了!
}
func f4(a [5]int) {
_ = a[4] // 第22行: 边界检查消除了!
}
func main() {}
$ go run -gcflags="-d=ssa/check_bce/debug=1" example1.go
./example1.go:5: Found IsInBounds
./example1.go:6: Found IsInBounds
./example1.go:7: Found IsInBounds
./example1.go:11: Found IsInBounds
./example1.go:17: Found IsInBounds
我们可以看到函数 f2 中的第 12 行和第 13 行不再需要边界检查了,因为第 11 行的检查确保了第 12 行和第 13 行中使用的下标肯定不会越界。
但是,函数 f1 中的三行仍然都需要边界检查,因为第 5 行中的边界检查不能保证第 6 行和第 7 行中的下标没有越界,第 6 行中的边界检查也不能保证第第 7 行中的下标没有越界。
在函数 f3 中,编译器知道如果第一个 s[index] 是安全的,则第二个 s[index] 是无需边界检查的。
编译器也正确地认为函数 f4 中的唯一一行(第 22 行)是无需边界检查的。
例子 2
// example2.go
package main
func f5(s []int) {
for i := range s {
_ = s[i]
_ = s[i:len(s)]
_ = s[:i+1]
}
}
func f6(s []int) {
for i := 0; i < len(s); i++ {
_ = s[i]
_ = s[i:len(s)]
_ = s[:i+1]
}
}
func f7(s []int) {
for i := len(s) - 1; i >= 0; i-- {
_ = s[i] // line22
_ = s[i:len(s)]
}
}
func f8(s []int, index int) {
if index >= 0 && index < len(s) {
_ = s[index]
_ = s[index:len(s)]
}
}
func f9(s []int) {
if len(s) > 2 {
_, _, _ = s[0], s[1], s[2]
}
}
func main() {}
$ go run -gcflags="-d=ssa/check_bce/debug=1" example2.go
官方标准编译器消除了上例程序中的所有边界检查。
注意:在 Go 官方工具链 1.11 之前,官方标准编译器没有足够聪明到认为第 22 行是不需要边界检查的。
例子 3
// example3.go
package main
import "math/rand"
func fa() {
s := []int{0, 1, 2, 3, 4, 5, 6}
index := rand.Intn(7)
_ = s[:index] // 第9行: 需要边界检查
_ = s[index:] // 第10行: 边界检查消除了!
}
func fb(s []int, index int) {
_ = s[:index] // 第14行: 需要边界检查
_ = s[index:] // 第15行: 需要边界检查(不够智能?)
}
func fc() {
s := []int{0, 1, 2, 3, 4, 5, 6}
s = s[:4]
index := rand.Intn(7)
_ = s[:index] // 第22行: 需�要边界检查
_ = s[index:] // 第23行: 需要边界检查(不够智能?)
}
func main() {}
$ go run -gcflags="-d=ssa/check_bce/debug=1" example3.go
./example3.go:9: Found IsSliceInBounds
./example3.go:14: Found IsSliceInBounds
./example3.go:15: Found IsSliceInBounds
./example3.go:22: Found IsSliceInBounds
./example3.go:23: Found IsSliceInBounds
噢,仍然有这么多的边界检查!
但是等等,为什么官方标准编译器认为第 10 行不需要边界检��查,却认为第 15 和第 23 行仍旧需要边界检查呢? 是标准编译器不够智能吗?
事实上,这里标准编译器做得对。原因是一个子切片表达式中的起始下标可能会大于基础切片的长度。
让我们先看一个简单的使用了子切片的例子:
package main
func main() {
s0 := make([]int, 5, 10)
// len(s0) == 5, cap(s0) == 10
index := 8
// 在Go中,对于一个子切片表达式s[a:b],a和b须满足
// 0 <= a <= b <= cap(s);否则,将产生一个恐慌。
_ = s0[:index]
// 上一行是安全的不能保证下一行是无需边界检查的。
// 事实上,下一行将产生一个恐慌,因为起始下标
// index大于终止下标(即切片s0的长度)。
_ = s0[index:] // panic
}
所以,“如果s[:index]是安全的,则s[index:]是无需边界检查的” 这条论述只有在 len(s) 和 cap(s) 相等的情况下才正确。这就是函数 fb 和 fc 中的代码仍旧需要边界检查的原因。
而在例子 3 中,标准编译器成功地检测到在函数 fa 中 len(s) 和 cap(s) 是相等的。
例子 4
// example4.go
package main
import "math/rand"
func fb2(s []int, index int) {
_ = s[index:] // 第7行: 需要边界检查
_ = s[:index] // 第8行: 边界检查消除了!
}
func fc2() {
s := []int{0, 1, 2, 3, 4, 5, 6}
s = s[:4]
index := rand.Intn(7)
_ = s[index:] // 第15行: 需要边界检查
_ = s[:index] // 第16行: 边界检查消除了!
}
func main() {}
$ go run -gcflags="-d=ssa/check_bce/debug=1" example4.go
./example4.go:7:7: Found IsSliceInBounds
./example4.go:15:7: Found IsSliceInBounds
在此例子中,标准编译器成功推断出:
- 在函数
fb2中,如果第 7 行是安全的,则第 8 行是无需边界检查的; - 在函数
fc2中,如果第 15 行是安全的,则第 16 行是无需边界检查的。
注意:Go 官方工具链 1.9 之前中的标准编译器没有出推断出第 8 行不需要边界检查。
例子 5
当前版本的标准编译器并非足够智能到可以消除到一切应该消除的边界检查。 有时候,我们需要给标准编译器一些暗示来帮助标准编译器将这些不必要的边界检查消除掉。
// example5.go
package main
func fd(is []int, bs []byte) {
if len(is) >= 256 {
for _, n := range bs {
_ = is[n] // 第7行: 需要边界检查
}
}
}
func fd2(is []int, bs []byte) {
if len(is) >= 256 {
is = is[:256] // 第14行: 一个暗示
for _, n := range bs {
_ = is[n] // 第16行: 边界检查消除了!
}
}
}
func fe(isa []int, isb []int) {
if len(isa) > 0xFFF {
for _, n := range isb {
_ = isa[n & 0xFFF] // 第24行: 需要边界检查
}
}
}
func fe2(isa []int, isb []int) {
if len(isa) > 0xFFF {
isa = isa[:0xFFF+1] // 第31行: 一个暗示
for _, n := range isb {
_ = isa[n & 0xFFF] // 第33行: 边界检查消除了!
}
}
}
func main() {}
$ go run -gcflags="-d=ssa/check_bce/debug=1" example5.go
./example5.go:7: Found IsInBounds
./example5.go:24: Found IsInBounds
总结
本文上面列出的例子并没有涵盖标准编译器支持的所有边界检查消除的情形。本文列出的仅仅是一些常见的情形。
尽管标准编译器中的边界检查消除特性依然不是 100% 完美,但是对很多常见的情形,它确实很有效。 自从标准编译器支持此特性以来,在每个版本更新中,此特性都在不断地改进增强。 无需质疑,在以后的版本中,标准编译器会更加得智能,以至于上面第 5 个例子中提供给编译器的暗示有可能将变得不再必要。
延迟函数调用
deferred function call
在 Go 中,一个函数调用可以跟在一个 defer 关键字后面,形成一个延迟函数调用。 和协程调用类似,被延迟的函数调用的所有返回值必须全部被舍弃。
当一个函数调用被延迟后,它不会立即被执行。它将被推入由当前协程维护的一个延迟调用堆栈。 当一个函数调用(可能是也可能不是一个延迟调用)返回并进入它的退出阶段后,所有在此函数调用中已经被推入的延迟调用将被按照它们被推入堆栈的顺序逆序执行。 当所有这些延迟调用执行完毕后,此函数调用也就真正退出了。
下面这个例子展示了如何使用延迟调用函数。
package main
import "fmt"
func main() {
defer fmt.Println("The third line.")
defer fmt.Println("The second line.")
fmt.Println("The first line.")
}
输出结果:
The first line.
The second line.
The third line.
事实上,每个协程维护着两个调用堆栈。
- 一个是正常的函数调用堆栈。在此堆栈中,相邻的两个调用存在着调用关系。晚进入堆栈的调用被早进入堆栈的调用所调用。 此堆栈中最早被推入的调用是对应协程的启动调用。
- 另一个堆栈是上面��提到的延迟调用堆栈。处于延迟调用堆栈中的任意两个调用之间不存在调用关系。
下面是另一个略微复杂一点的使用了延迟调用的例子程序。此程序将按照自然数的顺序打印出 0 到 9 十个数字。
package main
import "fmt"
func main() {
defer fmt.Println("9")
fmt.Println("0")
defer fmt.Println("8")
fmt.Println("1")
if false {
defer fmt.Println("not reachable")
}
defer func() {
defer fmt.Println("7")
fmt.Println("3")
defer func() {
fmt.Println("5")
fmt.Println("6")
}()
fmt.Println("4")
}()
fmt.Println("2")
return
defer fmt.Println("not reachable")
}
一个延迟调用可以修改包含此延迟调用的最内层函数的返回值
一个例子:
package main
import "fmt"
func Triple(n int) (r int) {
defer func() {
r += n // 修改返回值
}()
return n + n // <=> r = n + n; return
}
func main() {
fmt.Println(Triple(5)) // 15
}
延迟函数调用的必要性和好处
事实上,上面的几个使用了延迟函数调用的例子中的延迟函数调用并非绝对必要。 但是延迟调用对于下面将要介绍的恐慌 / 恢复特性是必要的。
另外延迟函数调用可以帮助我们写出更整洁和更鲁棒的代码。
⭐ 协程和延迟调用的实参的估值时刻
一个协程调用或者延迟调用的实参是在此调用发生时被估值的。更具体地说,
-
对于一个延迟函数��调用,它的实参是在此调用被推入延迟调用堆栈的时候被估值的。
-
对于一个协程调用,它的实参是在此协程被创建的时候估值的。
-
一个匿名函数体内的表达式是在此函数被执行的时候才会被逐个估值的,不管此函数是被普通调用还是延迟 / 协程调用。
一个例子:
package main
import "fmt"
func main() {
func() {
for i := 0; i < 3; i++ {
defer fmt.Println("a:", i) // 推入堆栈时被估值
}
}()
fmt.Println()
func() {
for i := 0; i < 3; i++ {
defer func() {
fmt.Println("b:", i) // 执行时被估值
}()
}
}()
}
运行之,将得到如下结果:
a: 2
a: 1
a: 0
b: 3
b: 3
b: 3
第一个匿名函数中的循环打印出 2、1 和 0 这个序列,但是第二个匿名函数中的循环打印出三个 3。 因为第一个循环中的 i 是在 fmt.Println 函数调用被推入延迟调用堆栈的时候估的值,而第二个循环中的 i 是在第二个匿名函数调用的退出阶段估的值(此时循环变量 i 的值已经变为 3)。
我们可以对第二个循环略加修改(使用两种方法),使得它和第一个循环打印出相同的结果。
for i := 0; i < 3; i++ {
defer func(i int) {
// 此i为形参i,非实参循环变量i。
fmt.Println("b:", i)
}(i)
}
或者
for i := 0; i < 3; i++ {
i := i // 在下面的调用中,左i遮挡了右i。
// <=> var i = i
defer func() {
// 此i为上面的左i,非循环变量i。
fmt.Println("b:", i)
}()
}
同样的估值时刻规则也适用于协程调用。下面这个例子程序将打印出 123 789。
package main
import "fmt"
import "time"
func main() {
var a = 123
go func(x int) { // x在创建时被估值
time.Sleep(time.Second)
fmt.Println(x, a) // 123 789
}(a)
a = 789
time.Sleep(2 * time.Second)
}
顺便说一句,使用
time.Sleep调用来做并发同步不是一个好的方法。 如果上面这个程序运行在一个满负荷运行的电脑上,此程序可能在新启动的协程可能还未得到执行机会的时候就已经退出了。
如何优雅地关闭通道
一些观点认为:
- 没有一个简单和通用的方法用来在不改变一个通道的状态的情况下检查这个通道是否已经关闭。
- 关闭一个已经关闭的通道将产生一个恐慌,所以在不知道一个通道是否已经关闭的时候关闭此通道是很危险的。
- 向一个已关闭的通道发送数据将产生一个恐慌,所以在不知道一个通道是否已经关闭的时候向此通道发送数据是很危险的。
是的,Go 语言中并没有提供一个内置函数来检查一个通道是否已经关闭。
在 Go 中,如果我们能够保证从不会向一个通道发送数据,那么有一个简单的方法来判断此通道是否已经关闭:
package main
import "fmt"
type T int
func IsClosed(ch <-chan T) bool {
select {
case <-ch:
return true
default:
}
return false
}
func main() {
c := make(chan T)
fmt.Println(IsClosed(c)) // false
close(c)
fmt.Println(IsClosed(c)) // true
}
如前所述,此方法并不是一个通用的检查通道是否已经关闭的方法。
事实上,即使有一个内置 closed 函数用来检查一个通道是否已经关闭,它的有用性也是十分有限的。 原因是当此函数的一个调用的结果返回时,被查询的通道的状态可能已经又改变了,导致此调用结果并不能反映出被查询的通道的最新状态。 虽然我们可以根据一个调用 closed(ch) 的返回结果为 true 而得出我们不应该再向通道 ch 发送数据的结论, 但是我们不能根据一个调用 closed(ch) 的返回结果为 false 而得出我们可以继续向通道 ch 发送数据的结论。
通道关闭原则
一个常用的使用 Go 通道的原则是不要在数据接收方或者在有多个发送者的情况下关闭通道。
换句话说,我们只应该让一个通道唯一的发送者关闭此通道。
下面我们将称此原则为通道关闭原则。
当然,这并不是一个通用的关闭通道的原则。通用的原则是不要关闭已关闭的通道。 如果我们能够保证从某个时刻之后,再没有协程将向一个未关闭的非 nil 通道发送数据,则一个协程可以安全地关闭此通道。 然而,做出这样的保证常常需要很大的努力,从而导致代码过度复杂。 另一方面,遵循通道关闭原则是一件相对简单的事儿。
粗鲁地关闭通道的方法
如果由于某种原因,你一定非要从数据接收方或者让众多发送者中的一个关闭一个通道,你可以使用恢复机制来防止可能产生的恐慌而导致程序崩溃。 下面就是这样的一个实现(假设通道的元素类型为T)。
func SafeClose(ch chan T) (justClosed bool) {
defer func() {
if recover() != nil {
// 一个函数的返回结果可以在defer调用中修改。
justClosed = false
}
}()
// 假设ch != nil。
close(ch) // 如果ch已关闭,则产生一个恐慌。
return true // <=> justClosed = true; return
}
此方法违反了通道关闭原则。
同样的方法可以用来粗鲁地向一个关闭状态未知的通道发送数据。
func SafeSend(ch chan T, value T) (closed bool) {
defer func() {
if recover() != nil {
closed = true
}
}()
ch <- value // 如果ch已关闭,则产生一个恐慌。
return false // <=> closed = false; return
}
这样的粗鲁方法不仅违反了通道关闭原则,而且 Go 白皮书和标准编译器不保证它的实现中不存在数据竞争。
礼貌地关闭通道的方法
很多 Go 程序员喜欢使用 sync.Once 来关闭通道。
type MyChannel struct {
C chan T
once sync.Once
}
func NewMyChannel() *MyChannel {
return &MyChannel{C: make(chan T)}
}
func (mc *MyChannel) SafeClose() {
mc.once.Do(func() {
close(mc.C)
})
}
当然,我们也可以使用 sync.Mutex 来防止多次关闭一个通道。
type MyChannel struct {
C chan T
closed bool
mutex sync.Mutex
}
func NewMyChannel() *MyChannel {
return &MyChannel{C: make(chan T)}
}
func (mc *MyChannel) SafeClose() {
mc.mutex.Lock()
defer mc.mutex.Unlock()
if !mc.closed {
close(mc.C)
mc.closed = true
}
}
func (mc *MyChannel) IsClosed() bool {
mc.mutex.Lock()
defer mc.mutex.Unlock()
return mc.closed
}
这些实现确实比上一节中的方法礼貌一些,但是它们不能完全有效地避免数据竞争。 目前的 Go 白皮书并不保证发生在一个通道上的并发关闭操作和发送操纵不会产生数据竞争。 如果一个 SafeClose 函数和同一个通道上的发送操作同时运行,则数据竞争可能发生(虽然这样的数据竞争一般并不会带来什么危害)。
优雅地关闭通道的方法
上一节中介绍的 SafeSend 函数有一个弊端,它的调用不能做为 case 操作而被使用在 select 代码块中。 另外,很多 Go 程序员认为上面两节展示的关闭通道的方法不是很优雅。 本节下面将介绍一些在各种情形下使用纯通道操作来关闭通道的方法。
为了演示程序的完整性,下面这些例子中使用到了
sync.WaitGroup。在实践中,sync.WaitGroup并不是必需的。
情形一
M 个接收者和一个发送者。发送者通过关闭用来传输数据的通道来传递发送结束信号
这是最简单的一种情形。当发送者欲结束发送,让它关闭用来传输数据的通道即可。
package main
import (
"time"
"math/rand"
"sync"
"log"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const Max = 100000
const NumReceivers = 100
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(NumReceivers)
// ...
dataCh := make(chan int)
// 发送者
go func() {
for {
if value := rand.Intn(Max); value == 0 {
// 此唯一的发送者可以安全地关闭此数据通道。
close(dataCh)
return
} else {
dataCh <- value
}
}
}()
// 接收者
for i := 0; i < NumReceivers; i++ {
go func() {
defer wgReceivers.Done()
// 接收数据直到通道dataCh已关闭
// 并且dataCh的缓冲队列已空。
for value := range dataCh {
log.Println(value)
}
}()
}
wgReceivers.Wait()
}
情形二
一个接收者和 N 个发送者,此唯一接收者通过关闭一个额外的信号通道来通知发送者不要在发送数据了
此情形比上一种情形复杂一些。我们不能让接收者关闭用来传输数据的通道来停止数据传输,因为这样做违反了通道关闭原则。 但是我们可以让接收者关闭一个额外的信号通道来通知发送者不要再发送数据了。
package main
import (
"time"
"math/rand"
"sync"
"log"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const Max = 100000
const NumSenders = 1000
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(1)
// ...
dataCh := make(chan int)
stopCh := make(chan struct{})
// stopCh是一个额外的信号通道。它的
// 发送者为dataCh数据通道的接收者。
// 它的接收者为dataCh数据通道的发送者。
// 发送者
for i := 0; i < NumSenders; i++ {
go func() {
for {
// 这里的第一个尝试接收用来让此发送者
// 协程尽早地退出。对于这个特定的例子,
// 此select代码块并非必需。
select {
case <- stopCh:
return
default:
}
// 即使stopCh已经关闭,此第二个select
// 代码块中的第一个分支仍很有可能在若干个
// 循环步内依然不会被选中。如果这是不可接受
// 的,则上面的第一个select代码块是必需的。
select {
case <- stopCh:
return
case dataCh <- rand.Intn(Max):
}
}
}()
}
// 接收者
go func() {
defer wgReceivers.Done()
for value := range dataCh {
if value == Max-1 {
// 此唯一的接收者同时也是stopCh通道的
// 唯一发送者。尽管它不能安全地关闭dataCh数
// 据通道,但它可以安全地关闭stopCh通道。
close(stopCh)
return
}
log.Println(value)
}
}()
// ...
wgReceivers.Wait()
}
如此例中的注释所述,对于此额外的信号通道 stopCh,它只有一个发送者,即 dataCh 数据通道的唯一接收者。 dataCh 数据通道的接收者关闭了信号通道 stopCh,这是不违反通道关闭原则的。
在此例中,数据通道 dataCh 并没有被关闭。是的,我们不必关闭它。 当一个通道不再被任何协程所使用后,它将逐渐被垃圾回收掉,无论它是否已经被关闭。 所以这里的优雅性体现在通过不关闭一个通道来停止使用此通道。
情形三
M 个接收者和 N 个发送者。它们中的任何协程都可以让一个中间调解协程帮忙发出停止数据传送的信号
这是最复杂的一种情形。我们不能让接收者和发送者中的任何一个关闭用来传输数据的通道,我们也不能让多个接收者之一关闭一个额外的信号通道。 这两种做法都违反了通道关闭原则。
然而,我们可以引入一个中间调解者角色并让其关闭额外的信号通道来通知所有的接收者和发送者结束工作。
具体实现见下例。注意其中使用了一个尝试发送操作来向中间调解者发送信号。
package main
import (
"time"
"math/rand"
"sync"
"log"
"strconv"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const Max = 100000
const NumReceivers = 10
const NumSenders = 1000
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(NumReceivers)
// ...
dataCh := make(chan int)
stopCh := make(chan struct{})
// stopCh是一个额外的信号通道。它的发送
// 者为中间调解者。它的接收者为dataCh
// 数据通道的所有的发送者和接收者。
toStop := make(chan string, 1)
// toStop是一个用来通知中间调解者让其
// 关闭信号通道stopCh的第二个信号通道。
// 此第二个信号通道的发送者为dataCh数据
// 通道的所有的发送者和接收者,它的接收者
// 为中间调解者。它必须为一个缓冲通道。
var stoppedBy string
// 中间调解者
go func() {
stoppedBy = <-toStop
close(stopCh)
}()
// 发送者
for i := 0; i < NumSenders; i++ {
go func(id string) {
for {
value := rand.Intn(Max)
if value == 0 {
// 为了防止阻塞,这里使用了一个尝试
// 发送操作来向中间调解者发送信号。
select {
case toStop <- "发送者#" + id:
default:
}
return
}
// 此处的尝试接收操作是为了让此发送协程尽早
// 退出。标准编译器对尝试接收和尝试发送做了
// 特殊的优化,因而它们的速度很快。
select {
case <- stopCh:
return
default:
}
// 即使stopCh已关闭,如果这个select代码块
// 中第二个分支的发送操作是非阻塞的,则第一个
// 分支仍很有可能在若干个循环步内依然不会被选
// 中。如果这是不可接受的,则上面的第一个尝试
// 接收操作代码块是必需的。
select {
case <- stopCh:
return
case dataCh <- value:
}
}
}(strconv.Itoa(i))
}
// 接收者
for i := 0; i < NumReceivers; i++ {
go func(id string) {
defer wgReceivers.Done()
for {
// 和发送者协程一样,此处的尝试接收操作是为了
// 让此接收协程尽早退出。
select {
case <- stopCh:
return
default:
}
// 即使stopCh已关闭,如果这个select代码块
// 中第二个分支的接收操作是非阻塞的,则第一个
// 分支仍很有可能在若干个循环步内依然不会被选
// 中。如果这是不可接受的,则上面尝试接收操作
// 代码块是必需的。
select {
case <- stopCh:
return
case value := <-dataCh:
if value == Max-1 {
// 为了防止阻塞,这里使用了一个尝试
// 发送操作来向中间调解者发送信号。
select {
case toStop <- "接收者#" + id:
default:
}
return
}
log.Println(value)
}
}
}(strconv.Itoa(i))
}
// ...
wgReceivers.Wait()
log.Println("被" + stoppedBy + "终止了")
}
在此例中,通道关闭原则依旧得到了遵守。
请注意!信号通道 toStop 的容量必须至少��为 1。 如果它的容量为 0,则在中间调解者还未准备好的情况下就已经有某个协程向 toStop 发送信号时,此信号将被抛弃。
我们也可以不使用尝试发送操作向中间调解者发送信号,但信号通道 toStop 的容量必须至少为数据发送者和数据接收者的数量之和,以防止向其发送数据时(有一个极其微小的可能)导致某些发送者和接收者协程永久阻塞。
...
toStop := make(chan string, NumReceivers + NumSenders)
...
value := rand.Intn(Max)
if value == 0 {
toStop <- "sender#" + id
return
}
...
if value == Max-1 {
toStop <- "receiver#" + id
return
}
...
情形四
“M 个接收者和一个发送者” 情形的一个变种:用来传输数据的通道的关闭请求由第三方发出
有时,数据通道(dataCh)的关闭请求需要由某个第三方协程发出。对于这种情形,我们可以使用一个额外的信号通道来通知唯一的发送者关闭数据通道(dataCh)。
package main
import (
"time"
"math/rand"
"sync"
"log"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const Max = 100000
const NumReceivers = 100
const NumThirdParties = 15
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(NumReceivers)
// ...
dataCh := make(chan int)
closing := make(chan struct{}) // 信号通道
closed := make(chan struct{})
// 此stop函数可以被安全地多次调用。
stop := func() {
select {
case closing<-struct{}{}:
<-closed
case <-closed:
}
}
// 一些第三方协程
for i := 0; i < NumThirdParties; i++ {
go func() {
r := 1 + rand.Intn(3)
time.Sleep(time.Duration(r) * time.Second)
stop()
}()
}
// 发送者
go func() {
defer func() {
close(closed) // 让stop函数正常退出而不会阻塞
close(dataCh)
}()
for {
select{
case <-closing: return
default:
}
select{
case <-closing: return
case dataCh <- rand.Intn(Max):
}
}
}()
// 接收者
for i := 0; i < NumReceivers; i++ {
go func() {
defer wgReceivers.Done()
for value := range dataCh {
log.Println(value)
}
}()
}
wgReceivers.Wait()
}
上述代码中的 stop 函数中使用的技巧偷自 Roger Peppe 在此贴中的一个留言。
情形五
“N 个发送者”的一个变种:用来传输数据的通道必须被关闭以通知各个接收者数据发送已经结束了
在上面的提到的 “N 个发送者” 情形中,为了遵守通道关闭原则,我们避免了关闭数据通道(dataCh)。 但是有时候,数据通道(dataCh)必须被关闭以通知各个接收者数据发送已经结束。 对于这种 “N 个发送者” 情形,我们可以使用一个中间通道将它们转化为“一个发送者”情形,然后继续使用上一节介绍的技巧来关闭此中间通道,从而避免了关闭原始的dataCh数据通道。
package main
import (
"time"
"math/rand"
"sync"
"log"
"strconv"
)
func main() {
rand.Seed(time.Now().UnixNano())
log.SetFlags(0)
// ...
const Max = 1000000
const NumReceivers = 10
const NumSenders = 1000
const NumThirdParties = 15
wgReceivers := sync.WaitGroup{}
wgReceivers.Add(NumReceivers)
// ...
dataCh := make(chan int) // 将被关闭
middleCh := make(chan int) // 不会被关闭
closing := make(chan string)
closed := make(chan struct{})
var stoppedBy string
stop := func(by string) {
select {
case closing <- by:
<-closed
case <-closed:
}
}
// 中间层
go func() {
exit := func(v int, needSend bool) {
close(closed)
if needSend {
dataCh <- v
}
close(dataCh)
}
for {
select {
case stoppedBy = <-closing:
exit(0, false)
return
case v := <- middleCh:
select {
case stoppedBy = <-closing:
exit(v, true)
return
case dataCh <- v:
}
}
}
}()
// 一些第三方协程
for i := 0; i < NumThirdParties; i++ {
go func(id string) {
r := 1 + rand.Intn(3)
time.Sleep(time.Duration(r) * time.Second)
stop("3rd-party#" + id)
}(strconv.Itoa(i))
}
// 发送者
for i := 0; i < NumSenders; i++ {
go func(id string) {
for {
value := rand.Intn(Max)
if value == 0 {
stop("sender#" + id)
return
}
select {
case <- closed:
return
default:
}
select {
case <- closed:
return
case middleCh <- value:
}
}
}(strconv.Itoa(i))
}
// 接收者
for range [NumReceivers]struct{}{} {
go func() {
defer wgReceivers.Done()
for value := range dataCh {
log.Println(value)
}
}()
}
// ...
wgReceivers.Wait()
log.Println("stopped by", stoppedBy)
}
更多情形?
在日常编程中可能会遇到更多的变种情形,但是上面介绍的情形是最常见和最基本的。 通过聪明地使用通道(和其它并发同步技术),我相信,对于各种变种,我们总会找到相应的遵守通道关闭原则的解决方法。
结论
并没有什么情况非得逼得我们违反通道关闭原则。 如果你遇到了此情形,请考虑修改你的代码流程和结构设计。
使用通道编程宛如在艺术创作一般!
Go中的 nil
nil 是 Go 中的一个使用频率很高的预声明标识符。 很多种类的类型的零值都用 nil 表示。 很多有其它语言编程经验的程序员在初学 Go 语言的时候常将 nil 看成是其它语言中的 null 或者 NULL。 这种看法只是部分上正��确的,但是 Go 中的 nil 和其它语言中的 null 或者 NULL 也是有很大的区别的。
本文的剩余部分将列出和 nil 相关的各种事实。
nil 是一个预声明的标识符
我们可以直接使用它。
预声明的 nil 标识符可以表示很多种类型的零值
在 Go 中,预声明的 nil 可以表示下列种类(kind)的类型的零值:
- 指针类型(包括类型安全和非类型安全指针)
- 映射类型
- 切片类型
- 函数类型
- 通道类型
- 接口类型
预声明标识符 nil 没有默认类型
Go 中其它的预声明标识符都有各自的默认类型,比如
- 预声明标识符
true和false的默认类型均为内置类型bool。 - 预声明标识符
iota的默认类型为内置类型int。
但是,预声明标识符 nil 没有一个默认类型,尽管它有很多潜在的可能类型。 事实上,预声明标识符 nil 是 Go 中唯一一个没有默认类型的类型不确定值。 我们必须在代码中提供足够的信息以便让编译器能够推断出一个类型不确定的 nil 值的期望类型。
一个例子:
package main
func main() {
// 代码中必须提供充足的信息来让编译器推断出某个nil的类型。
_ = (*struct{})(nil)
_ = []int(nil)
_ = map[int]bool(nil)
_ = chan string(nil)
_ = (func())(nil)
_ = interface{}(nil)
// 下面这一组和上面这一组等价。
var _ *struct{} = nil
var _ []int = nil
var _ map[int]bool = nil
var _ chan string = nil
var _ func() = nil
var _ interface{} = nil
// 下面这行编译不通过。
var _ = nil
}
nil 不是一个关键字
预声明标识符 nil 可以被更内层的同名标识符所遮挡。
一个例子:
package main
import "fmt"
func main() {
nil := 123
fmt.Println(nil) // 123
// 下面这行编译报错,因为此行中的nil是一个int值。
var _ map[string]int = nil
}
(顺便说一下,其它语言中的 null 和 NULL 也不是关键字。)
不同种类的类型的 nil 值的尺寸很可能不相同
一个类型的所有值的内存布局都是一样的,此类型 nil 值也不例外(假设此类型的零值使用 nil 表示)。 所以同一个类型的 nil 值和非 nil 值的尺寸是一样的。但是不同类型的 nil 值的尺寸可能是不一样的。
一个例子:
package main
import (
"fmt"
"unsafe"
)
func main() {
var p *struct{} = nil
fmt.Println( unsafe.Sizeof( p ) ) // 8
var s []int = nil
fmt.Println( unsafe.Sizeof( s ) ) // 24
var m map[int]bool = nil
fmt.Println( unsafe.Sizeof( m ) ) // 8
var c chan string = nil
fmt.Println( unsafe.Sizeof( c ) ) // 8
var f func() = nil
fmt.Println( unsafe.Sizeof( f ) ) // 8
var i interface{} = nil
fmt.Println( unsafe.Sizeof( i ) ) // 16
}
上例打印出来的尺寸值取决于系统架构和具体编译器实现。 上例中的输出是使用官方标准编译器编译并在 64 位的系统架构上运行的结果。 在 32 位的系统架构上,这些输出值将减半。
对于官方标准编译器,如果两个类型属于同一种(kind)类型,并且它们的零值用nil表示,则这两个类型的尺寸肯定相等。
两个不同类型的 nil 值可能不能相互比较
比如,下例中的两行中的比较均编译不通过。
// error: 类型不匹配
var _ = (*int)(nil) == (*bool)(nil)
// error: 类型不匹配
var _ = (chan int)(nil) == (chan bool)(nil)
请阅读 Go 中的值比较规则来了解哪些值可以相互比较。 类型确定的 nil 值也要遵循这些规则。
下面这些比较是合法的:
type IntPtr *int
// 类型IntPtr的底层类型为*int。
var _ = IntPtr(nil) == (*int)(nil)
// 任何类型都实现了interface{}类型。
var _ = (interface{})(nil) == (*int)(nil)
// 一个双向通道可以隐式转换为和它的
// 元素类型一样的单项通道类型。
var _ = (chan int)(nil) == (chan<- int)(nil)
var _ = (chan int)(nil) == (<-chan int)(nil)
同一个类型的两个 nil 值可能不能相互比较
在 Go 中,映射类型、切片类型和函数类型是不支持比较类型。 比较同一个不支持比较的类型的两个值(包括 nil 值)是非法的。 比如,下面的几个比较都编译不通过。
var _ = ([]int)(nil) == ([]int)(nil)
var _ = (map[string]int)(nil) == (map[string]int)(nil)
var _ = (func())(nil) == (func())(nil)
但是,映射类型、切片类型和函数类型的任何值都可以和类型不确定的裸nil标识符比较。
// 这几行编译都没问题。
var _ = ([]int)(nil) == nil
var _ = (map[string]int)(nil) == nil
var _ = (func())(nil) == nil
两个 nil 值可能并不相等
如果可被比较的两个 nil 值中的一个的类型为接口类型,而另一个不是,则比较结果总是false。 原因是,在进行此比较之前,此非接口 nil 值将被转换为另一个 nil 值的接口类型,从而将此比较转化为两个接口值的比较。 从接口一文中,我们得知每个接口值可以看作是一个包裹非接口值的盒子。 一个非接口值被转换为一个接口类型的过程可以看作是用一个接口值将此非接口值包裹起来的过程。 一个 nil 接口值中什么也没包裹,但是一个包裹了 nil 非接口值的接口值并非什么都没包裹。 一个什么都没包裹的接口值和一个包裹了一个非接口值(即使它是 nil)的接口值是不相等的。
一个例子:
fmt.Println( (interface{})(nil) == (*int)(nil) ) // false
访问 nil 映射值的条目不会产生恐慌
访问一个 nil 映射将得到此映射的类型的元素类型的零值。
比如:
fmt.Println( (map[string]int)(nil)["key"] ) // 0
fmt.Println( (map[int]bool)(nil)[123] ) // false
fmt.Println( (map[int]*int64)(nil)[123] ) //
range 关键字后可以跟随 nil 通道、nil 映射、nil 切片和 nil 数组指针
遍历 nil 映射和 nil 切片的循环步数均为零。
遍历一个 nil 数组指针的循环步数为对应数组类型的长度。 (但是,如果此数组类型的长度不为零并且第二个循环变量未被舍弃或者忽略,则对应for-range循环将导致一个恐慌。)
遍历一个 nil 通道将使当前协程永久阻塞。
比如,下面的代码将输出0、1、2、3和4后进入阻塞状态。 Hello、world和Bye不会被输出。
for range []int(nil) {
fmt.Println("Hello")
}
for range map[string]string(nil) {
fmt.Println("world")
}
for i := range (*[5]int)(nil) {
fmt.Println(i)
}
for range chan bool(nil) { // 阻塞在此
fmt.Println("Bye")
}
通过nil非接口属主实参调用方法不会造成恐慌
一个例子:
package main
type Slice []bool
func (s Slice) Length() int {
return len(s)
}
func (s Slice) Modify(i int, x bool) {
s[i] = x // panic if s is nil
}
func (p *Slice) DoNothing() {
}
func (p *Slice) Append(x bool) {
*p = append(*p, x) // 如果p为空指针,则产生一个恐慌。
}
func main() {
// 下面这几行中的选择器不会造成恐慌。
_ = ((Slice)(nil)).Length
_ = ((Slice)(nil)).Modify
_ = ((*Slice)(nil)).DoNothing
_ = ((*Slice)(nil)).Append
// 这两行也不会造成恐慌。
_ = ((Slice)(nil)).Length()
((*Slice)(nil)).DoNothing()
// 下面这两行都会造成恐慌。但是恐慌不是因为nil
// 属主实参造成的。恐慌都来自于这两个方法内部的
// 对空指针的解引用操作。
/*
((Slice)(nil)).Modify(0, true)
((*Slice)(nil)).Append(true)
*/
}
事实上,上面的Append方法实现不完美。我们应该像下面这样实现之:
func (p *Slice) Append(x bool) {
if p == nil {
*p = []bool{x}
return
}
*p = append(*p, x)
}
如果类型T的零值可以用预声明的nil标识符表示,则*new(T)的估值结果为一个T类型的nil值
一个例子:
package main
import "fmt"
func main() {
fmt.Println(*new(*int) == nil) // true
fmt.Println(*new([]int) == nil) // true
fmt.Println(*new(map[int]bool) == nil) // true
fmt.Println(*new(chan string) == nil) // true
fmt.Println(*new(func()) == nil) // true
fmt.Println(*new(interface{}) == nil) // true
}
总结一下
在 Go 中,为了简单和方便,nil被设计成一个可以表示成很多种类型的零值的预声明标识符。 换句话说,它可以表示很多内存布局不同的值,而不仅仅是一个值。
恐慌(panic)和恢复(recover)
Go 不支持异常抛出和捕获,而是推荐使用返回值显式返回错误。 不过,Go 支持一套和异常抛出 / 捕获类似的机制。此机制称为恐慌 / 恢复(panic/recover)机制。
我们可以调用内置函数 panic 来产生一个恐慌以使当前协程进入恐慌状况。
进入恐慌状况是另一种使当前函数调用开始返回的途径。 一旦一个函数调用产生一个恐慌,此函数调用将立即进入它的退出阶段,在此函数调用中被推入堆栈的延迟调用将按照它们被推入的顺序逆序执行。
通过在一个延迟函数调用之中调用内置函数 recover,当前协程中的一个恐慌可以被消除,从而使得当前协程重新进入正常状况。
在一个处于恐慌状况的协程退出之前,其中的恐慌不会蔓延到其它协程;如果一个协程在恐慌状况下退出,它将使整个程序崩溃。
内置函数 panic 和 recover 的声明原型如下:
func panic(v interface{})
func recover() interface{}
在一个 panic 函数调用中,我们可以传任何实参值。
一个 recover 函数的返回值为其所恢复的恐慌在产生时被一个 panic 函数调用所消费的参数。
下面这个例子展示了如何产生一个恐慌和如何消除一个恐慌。
package main
import "fmt"
func main() {
defer func() {
fmt.Println("正常退出")
}()
fmt.Println("嗨!")
defer func() {
v := recover()
fmt.Println("恐慌被恢复了:", v)
}()
panic("拜拜!") // 产生一个恐慌
fmt.Println("执行不到这里")
}
它的输出结果:
嗨!
恐慌被恢复了: 拜拜!
正常退出
下面的例子在一个新协程里面产生了一个恐慌,并且此协程在恐慌状况下退出,所以整个程序崩溃了。
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("hi!")
go func() {
time.Sleep(time.Second)
panic(123)
}()
for {
time.Sleep(time.Second)
}
}
运行之,输出如下:
hi!
panic: 123
goroutine 5 [running]:
...
Go 运行时(runtime)会在若干情形下产生恐慌,比如一个整数被 0 除的时候。下面这个程序将崩溃退出。
package main
func main() {
a, b := 1, 0
_ = a/b
}
它的输出:
panic: runtime error: integer divide by zero
goroutine 1 [running]:
...
一般说来,恐慌用来表示正常情况下不应该发生的逻辑错误。 如果这样的一个错误在运行时刻发生了,则它肯定是由于某个 bug 引起的。 另一方面,非逻辑错误是现实中难以避免的错误,它们不应该导致恐慌。 我们必须正确地对待和处理非逻辑错误。
对于官方标准编译器来说,很多致命性错误(比如堆栈溢出和内存不足)不能被恢复。它们一旦产生,程序将崩溃。
一些恐慌/恢复用例
用例1:避免恐慌导致程序崩溃
这可能是最常见的 panic/recover 用例了。 此用例广泛地使用于并发程序中,尤其是响应大量用户请求的应用。
一个例子:
package main
import "errors"
import "log"
import "net"
func main() {
listener, err := net.Listen("tcp", ":12345")
if err != nil {
log.Fatalln(err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Println(err)
}
// 在一个新协程中处理客户端连接。
go ClientHandler(conn)
}
}
func ClientHandler(c net.Conn) {
defer func() {
if v := recover(); v != nil {
log.Println("捕获了一个恐慌:", v)
log.Println("防止了程序崩溃")
}
c.Close()
}()
panic("未知错误") // 演示目的产生的一个恐慌
}
运行此服务器程序,并在另一个终端窗口运行telnet localhost 12345,我们可以观察到服务器程序不会因为客户连接处理协程中的产生的恐慌而导致崩溃。
如果我们在上例中不捕获客户连接处理协程中的潜在恐慌,则这样的恐慌将使整个程序崩溃。
用例2:自动重启因为恐慌而退出的协程
当在一个协程将要退出时,程序侦测到此协程是因为一个恐慌而导致此次退出时,我们可以立即重新创建一个相同功能的协程。 一个例子:
package main
import "log"
import "time"
func shouldNotExit() {
for {
time.Sleep(time.Second) // 模拟一个工作负载
// 模拟一个未预料到的恐慌。
if time.Now().UnixNano() & 0x3 == 0 {
panic("unexpected situation")
}
}
}
func NeverExit(name string, f func()) {
defer func() {
if v := recover(); v != nil { // 侦测到一个恐慌
log.Printf("协程%s崩溃了,准备重启一个", name)
go NeverExit(name, f) // 重启一个同功能协程
}
}()
f()
}
func main() {
log.SetFlags(0)
go NeverExit("job#A", shouldNotExit)
go NeverExit("job#B", shouldNotExit)
select{} // 永久阻塞主线程
}
用例3:使用panic/recover函数调用模拟长程跳转
有时,我们可以使用panic/recover函数调用来模拟跨函数跳转,尽管一般这种方式并不推荐使用。 这种跳转方式的可读性不高,代码效率也不是很高,唯一的好处是它有时可以使代码看上去不是很啰嗦。
在下面这个例子中,一旦一个恐慌在一个内嵌函数中产生,当前协程中的执行将会跳转到延迟调用处。
package main
import "fmt"
func main() {
n := func () (result int) {
defer func() {
if v := recover(); v != nil {
if n, ok := v.(int); ok {
result = n
}
}
}()
func () {
func () {
func () {
// ...
panic(123) // 用恐慌来表示成功返回
}()
// ...
}()
}()
// ...
return 0
}()
fmt.Println(n) // 123
}
用例4:使用panic/recover函数调用来减少错误检查代码
一个例子:
func doSomething() (err error) {
defer func() {
err = recover()
}()
doStep1()
doStep2()
doStep3()
doStep4()
doStep5()
return
}
// 在现实中,各个doStepN函数的原型可能不同。
// 每个doStepN函数的行为如下:
// * 如果已经成功,则调用panic(nil)来制造一个恐慌
// 以示不需继续;
// * 如果本步失败,则调用panic(err)来制造一个恐慌
// 以示不需继续;
// * 不制造任何恐慌表示继续下一步。
func doStepN() {
...
if err != nil {
panic(err)
}
...
if done {
panic(nil)
}
}
下面这段同功能的代码比上面这段代码看上去要啰嗦一些。
func doSomething() (err error) {
shouldContinue, err := doStep1()
if !shouldContinue {
return err
}
shouldContinue, err = doStep2()
if !shouldContinue {
return err
}
shouldContinue, err = doStep3()
if !shouldContinue {
return err
}
shouldContinue, err = doStep4()
if !shouldContinue {
return err
}
shouldContinue, err = doStep5()
if !shouldContinue {
return err
}
return
}
// 如果返回值err不为nil,则shouldContinue一定为true。
// 如果shouldContinue为true,返回值err可能为nil或者非nil。
func doStepN() (shouldContinue bool, err error) {
...
if err != nil {
return false, err
}
...
if done {
return false, nil
}
return true, nil
}
但是,这种panic/recover函数调用的使用方式一般并不推荐使用,因为它的效率略低一些,并且这种用法不太符合 Go 编程习俗。
详解恐慌和恢复原理
函数调用的退出阶段
在 Go 中,一个函数调用在其退出完毕之前可能将经历一个退出阶段。 在此退出阶段,所有在执行此函数调用期间被推入延迟调用堆栈的延迟函数调用将按照它们的推入顺序的逆序被执行。 当这些延迟函数调用都退出完毕之后,此函数调用的退出阶段也就结束了,或者说此函数调用也退出完毕了,
退出阶段有时候也�被称为返回阶段。
一个函数调用可能通过三种途径进入它的退出阶段:
- 此调用正常返回;
- 当此调用中产生了一个恐慌;
- 当
runtime.Goexit函数在此调用中被调用并且退出完毕。
比如,在下面这段代码中,
- 函数
f0或者f1的一个调用将在它正常返回后进入它的退出阶段; - 函数
f2的一个调用将在“被零除”恐慌产生之后进入它的退出阶段; - 函数
f3的一个调用将在其中的runtime.Goexit函数调用退出完毕之后进入它的退出阶段。
import (
"fmt"
"runtime"
)
func f0() int {
var x = 1
defer fmt.Println("正常退出:", x)
x++
return x
}
func f1() {
var x = 1
defer fmt.Println("正常退出:", x)
x++
}
func f2() {
var x, y = 1, 0
defer fmt.Println("因恐慌而退出:", x)
x = x / y // 将产生一个恐慌
x++ // 执行不到
}
func f3() int {
x := 1
defer fmt.Println("因Goexit调用而退出:", x)
x++
runtime.Goexit()
return x+x // 执行不到
}
函数调用关联恐慌和Goexit信号
当一个函数调用中直接产生了一个恐慌的时候,我们可以认为此(尚未被恢复的)恐慌将和此函数调用相关联起来。 类似地,当一个函数调用直接调用了runtime.Goexit函数,则runtime.Goexit函数返回完毕之后,我们可以认为一个 Goexit 信号将和此函数调用相关联起来。 恐慌和 Goexit 信号互相独立于对方,两者互不干扰。 按照上一节中的解释,当一个恐慌或者一个 Goexit 信号和一个函数调用相关联之后,此函数调用将立即进入它的退出阶段。
我们已经了解到恐慌是可以被恢复的。 但是,Goexit 信号是不能被取消的。
在任何一个给定时刻,一个函数调用最多只能和一个未恢复的恐慌相关联。 如果一个调用正和一个未恢复的恐慌相关联,则
- 在此恐慌被恢复之后,此调用将不再和任何恐慌相关联。
- 当在此函数调用中产生了一个新的恐慌,此新恐慌将替换原来的未被恢复的恐慌做为和此函数调用相关联的恐慌。
比如,在下面这个例子中,最终被恢复的恐慌是恐慌 3。它是最后一个和main函数调用相关联的恐慌。
package main
import "fmt"
func main() {
defer func() {
fmt.Println(recover()) // 3
}()
defer panic(3) // 将替换恐慌2
defer panic(2) // 将替换恐慌1
defer panic(1) // 将替换恐慌0
panic(0)
}
因为 Goexit 信号不可被取消,争论一个函数调用是否最多只能和一个 Goexit 信号相关联是没有意义和没有必要的。
在某个时刻,一个协程中可能共存多个未被恢复的恐慌,尽管这在实际编程中并不常见。 每个未被恢复�的恐慌和此协程的调用堆栈中的一个尚未退出的函数调用相关联。 当仍和一个未被恢复的恐慌相关联的一个内层函数调用退出完毕之后,此未被恢复的恐慌将传播到调用此内层函数调用的外层函数调用中。 这和在此外层函数调用中直接产生一个新的恐慌的效果是一样的。也就是说,
- 如果此外层函数已经和一个未被恢复的旧恐慌相关联,则传播出来的新恐慌将替换此旧恐慌并和此外层函数调用相关联起来。 对于这种情形,此外层函数调用肯定已经进入了它的退出阶段(刚提及的内层函数肯定就是被延迟调用的),这时延迟调用堆栈中的下一个延迟调用将被执行。
- 如果此外层函数尚未和一个未被恢复的旧恐慌相关联,则传播出来的恐慌将和此外层函数调用相关联起来。 对于这种情形,如果此外层函数调用尚未进入它的退出阶段,则它将立即进入。
所以,当一个协程完成完毕后,此协程中最多只有一个尚未被恢复的恐慌。 如果一个协程带着一个尚未被恢复的恐慌退出完毕,则这将使整个程序崩溃,此恐慌信息将在程序崩溃的时候被打印出来。
在一个函数调用被执行的起始时刻,此调用将没有任何恐慌和 Goexit 信号和它相关联,这个事实和此函数调用的外层调用是否已经进入退出阶段无关。 当然,在此函数调用的执行过程中,恐慌可能产生,runtime.Goexit函数也可能被调用,因此恐慌和 Goexit 信号以后可能和此调用相关联起来。
下面这个例子程序在运行时将崩溃,因为新开辟的协程在退出完毕时仍带有一个未被恢复的恐慌。
package main
func main() {
// 新开辟一个协程。
go func() {
// 一个匿名函数调用。
// 当它退出完毕时,恐慌2将�传播到此新协程的入口
// 调用中,并且替换掉恐慌0。恐慌2永不会被恢复。
defer func() {
// 上一个例子中已经解释过了:恐慌2将替换恐慌1.
defer panic(2)
// 当此匿名函数调用退出完毕后,恐慌1将传播到刚
// 提到的外层匿名函数调用中并与之关联起来。
func () {
panic(1)
// 在恐慌1产生后,此新开辟的协程中将共存
// 两个未被恢复的恐慌。其中一个(恐慌0)
// 和此协程的入口函数调用相关联;另一个
// (恐慌1)和当前这个匿名调用相关联。
}()
}()
panic(0)
}()
select{}
}
此程序的输出(当使用标准编译器 1.17 版本编译):
panic: 0
panic: 1
panic: 2
goroutine 5 [running]:
...
此输出的格式并非很完美,它容易让一些程序员误认为恐慌 0 是最终未被恢复的恐慌。而事实上,恐慌 2 才是最终未被恢复的恐慌。
类似地,当一个和 Goexit 信号相关联的内层函数调用退出完毕后,此 Goexit 信号也将传播到外层函数调用中,并和外层函数调用相关联起来。 如果外层函数调用尚未进入退出阶段,则其将立即进入。
上面提到了恐慌和 Goexit 信号是互不干扰的。 换句话说,一个尚未被恢复的恐慌不会导致一个 Goexit 信号被取消;一个 Goexit 信号也不会压制遮挡一个尚未被恢复的恐慌。 不过目前最新版本的官方两个编译器(标准编译器 v1.17 和 gccgo v8.0)都并未正确实现此规则。 比如,下面这个程序本应崩溃退出,但是并没有(使用最新版本的标准编译器和 gccgo 编译器编译)。
package main
import "runtime"
func f() {
// 此调用产生的Goexit信号将压制先前
// 产生的恐慌"bye",但是不应该如此。
defer runtime.Goexit()
panic("bye")
}
func main() {
go f()
for runtime.NumGoroutine() > 1 {
runtime.Gosched()
}
}
标准编译器和 gccgo 编译器将在以后的版本中修复此问题。
下面这个例子程序运行时应该马上退出,但是当前版本的 gccgo 编译器(v8.0)和 Go 官方工具链 1.14 之前的官方标准编译器均未正确实现之,从而导致此程序在运行时永不退出。
package main
import "runtime"
func f() {
defer func() {
recover()
}()
defer panic("将取消Goexit信号但是不应该这样")
runtime.Goexit()
}
func main() {
c := make(chan struct{})
go func() {
defer close(c)
f()
for {
runtime.Gosched()
}
}()
<-c
}
标准编译器从 1.14 版本开始修复了此问题。
一些recover调用相当于空�操作(No-Op)
内置recover函数必须在合适的位置调用才能发挥作用;否则,它的调用相当于空操作。 比如,在下面这个程序中,没有一个recover函数调用恢复了恐慌bye。
package main
func main() {
defer func() {
defer func() {
recover() // 空操作
}()
}()
defer func() {
func() {
recover() // 空操作
}()
}()
func() {
defer func() {
recover() // 空操作
}()
}()
func() {
defer recover() // 空操作
}()
func() {
recover() // 空操作
}()
recover() // 空操作
defer recover() // 空操作
panic("bye")
}
我们已经知道下面这个recover调用是有作用的。
package main
func main() {
defer func() {
recover() // 将恢复恐慌"byte"
}()
panic("bye")
}
那么为什么本节中的第一个例子中的所有recover调用都不起作用呢? 让我们先看看当前版本的Go白皮书是怎么说的:
在下面的情况下,recover函数调用的返回值为nil:
- 传递给相应
panic函数调用的实参为 nil; - 当前协程并没有处于恐慌状态;
recover函数并未直接在一个延迟函数调用中调用。
上一篇文章中提供了一个第一种情况的例子。
本节中的第一个例子中的大多recover调用要么符合 Go 白皮书中描述的第二种情况,要么符合第三种情况,除了第一个recover调用。 是的,当前版本的白皮书中的描述并不准确。此描述正在被改进中。
事实上,当前版本的白皮书也没有解释清楚为什么下面这个例子中的第二个recover调用没有起作用。此调用本用来恢复恐慌 1。
// 此程序将带着未被恢复的恐慌1而崩溃退出。
package main
func demo() {
defer func() {
defer func() {
recover() // 此调用将恢复恐慌2
}()
defer recover() // 空操作
panic(2)
}()
panic(1)
}
func main() {
demo()
}
当前版本的白皮书没提到的一点是:在任何时刻,一个协程中只有最新产生的恐慌才能够被恢复。 换句话说,每个recover调用都试图恢复当前协程中最新产生的且尚未恢复的恐慌。 这解释了为什么上例中的第二个recover调用不会起作用。
好了,到此我们可以对哪些recover调用会起作用做一个简短的描述:
一个recover调用只有在它的直接外层调用(即recover调用的父调用)是一个延迟调用,并且此延迟调用(即父调用)的直接外层调用(即recover调用的爷调用)和当前协程中最新产生并且尚未恢复的恐慌相关联时才起作用。一个有效的recover调用将最新产生并且尚未恢复的恐慌和与此恐慌相关联的函数调用(即爷调用)剥离开来,并且返回当初传递给产生此恐慌的panic函数调用的参数。
类型转换、赋值和值比较规则大全
此篇文章将列出 Go 中所有的类型转换、赋值和值比较规则。
类型转换规则大全
在 Go 中,如果一个值v可以被显式地转换为类型T,则此转换可以使用语法形式(T)(v)来表示。 在大多数情况下,特别是T为一个类型名(即一个标识符)时,此形式可简化为T(v)。
当我们说一个值x可以被隐式转换为一个类型T,这同时也意味着x可以被显式转换为类型T。
1. 显然的类型转换规则
如果两个类型表示着同一个类型,则它们的值可以相互隐式转换为这两个类型中的任意一个。
比如,
- 类型
byte和uint8的任何值可以转换为这两个类型中的任意一个。 - 类型
rune和int32的任何值可以转换为这两个类型中的任意一个。 - 类型
[]byte和[]uint8的任何值可以转换为这两个类型中的任意一个。
此条规则没什么可解释的,无论你是否认为此种情况中发生了转换。
2. 底层类型相关的类型转换规则
给定一个非接口值x和一个非接口类型T,并假设x的类型为Tx,
- 如果类型
Tx和T的底层类型相同(忽略掉结构体字段标签),则x可以被显式转换为类型T。 - 如果类型
Tx和T中至少有一个是非定义类型并且它们的底层类型相同(考虑结构体字段标签),则x可以被隐式转换为类型T。 - 如果类型
Tx和T的底层类型不同,但是两者都是非定义的指针类型并且它们的基类型的底层类型相同(忽略掉结构体字段标签),则x可以(而且只能)被显式转换为类型T。
(注意:两处“忽略掉结构体字段标签”从Go 1.8开始生效。)
一个例子:
package main
func main() {
// 类型[]int、IntSlice和MySlice共享底层类型:[]int。
type IntSlice []int
type MySlice []int
var s = []int{}
var is = IntSlice{}
var ms = MySlice{}
var x struct{n int `foo`}
var y struct{n int `bar`}
// 这两行隐式转换编译不通过。
/*
is = ms
ms = is
*/
// 必须使用显式转换。
is = IntSlice(ms)
ms = MySlice(is)
x = struct{n int `foo`}(y)
y = struct{n int `bar`}(x)
// 这些隐式转换是没问题的。
s = is
is = s
s = ms
ms = s
}
指针相关的转换例子:
package main
func main() {
type MyInt int
type IntPtr *int
type MyIntPtr *MyInt
var pi = new(int) // pi的类型为*int
var ip IntPtr = pi // 没问题,因为底层类型相同
// 并且pi的类型为非定义类型。
// var _ *MyInt = pi // 不能隐式转换
var _ = (*MyInt)(pi) // 显式转换是没问题的
// 类型*int的值不能被直接转换为类型MyIntPtr,
// 但是可以间接地转换过去。
/*
var _ MyIntPtr = pi // 不能隐式转换
var _ = MyIntPtr(pi) // 也不能显式转换
*/
var _ MyIntPtr = (*MyInt)(pi) // 间接隐式转换没问题
var _ = MyIntPtr((*MyInt)(pi)) // 间接显式转换没问题
// 类型IntPtr的值不能被直接转换为类型MyIntPtr,
// 但是可以间接地转换过去。
/*
var _ MyIntPtr = ip // 不能隐式转换
var _ = MyIntPtr(ip) // 也不能显式转换
*/
// 间接隐式或者显式转换都是没问题的。
var _ MyIntPtr = (*MyInt)((*int)(ip)) // ok
var _ = MyIntPtr((*MyInt)((*int)(ip))) // ok
}
3. 通道相关的类型转换规则
给定一个通道值x,假设它的类型Tx是一个双向通道类型,T也是一个通道类型(无论是双向的还是单向的)。如果Tx和T的元素类型相同并且它们中至少有一个为非定义类型,则x可以被隐式转换为类型T。
一个例子:
package main
func main() {
type C chan string
type C1 chan<- string
type C2 <-chan string
var ca C
var cb chan string
cb = ca // ok,因为底层类型相同
ca = cb // ok,因为底层类型相同
// 这4行都满足此第3条转换规则的条件。
var _, _ chan<- string = ca, cb // ok
var _, _ <-chan string = ca, cb // ok
var _ C1 = cb // ok
var _ C2 = cb // ok
// 类型C的值不能直接转换为类型C1或C2。
/*
var _ = C1(ca) // compile error
var _ = C2(ca) // compile error
*/
// 但是类型C的值可以间接转换为类型C1或C2。
var _ = C1((chan<- string)(ca)) // ok
var _ = C2((<-chan string)(ca)) // ok
var _ C1 = (chan<- string)(ca) // ok
var _ C2 = (<-chan string)(ca) // ok
}
4. 和接口实现相关的类型转换规则
给定一个值x和一个接口类型I,如果x的类型(或者默认类型)为Tx并且类型Tx实现了接口类型I,则x�可以被
隐式
转换为类型I。 此转换的结果为一个类型为I的接口值。此接口值包裹了
x的一个副本(如果Tx是一个非接口值);x的动态值的一个副本(如果Tx是一个接口值)。
请阅读接口一文获取更多详情和示例。
5. 类型不确定值相关的类型转换规则
如果一个类型不确定值可以表示为类型T的值,则它可以被隐式转换为类型T。
一个例子:
package main
func main() {
var _ []int = nil
var _ map[string]int = nil
var _ chan string = nil
var _ func()() = nil
var _ *bool = nil
var _ interface{} = nil
var _ int = 123.0
var _ float64 = 123
var _ int32 = 1.23e2
var _ int8 = 1 + 0i
}
6. 常量相关的类型转换规则
(此规则和上一条规则有些重叠。)
常量的类型转换结果一般仍然是一个常量。(除了下面第 8 条规则中将介绍的字符串转换为字节切片或者码点切片的情况。)
给定一个常量值x和一个类型T,如果x��可以表示成类型T的一个值,则x可以被显式地转换为类型T;特别地,如果x是一个类型不确定值,则它可以被隐式转换为类型T。
一个例子:
package main
func main() {
const I = 123
const I1, I2 int8 = 0x7F, -0x80
const I3, I4 int8 = I, 0.0
const F = 0.123456789
const F32 float32 = F
const F32b float32 = I
const F64 float64 = F
const F64b = float64(I3) // 这里必须显式转换
const C1, C2 complex64 = F, I
const I5 = int(C2) // 这里必须显式转换
}
7. 非常量数值转换规则
非常量浮点数和整数值可以被显式转换为任何浮点数和整数类型。
非常量复数值可以被显式转换为任何复数类型。
注意,
- 非常量复数值不能被转换为浮点数或整数类型。
- 非常量浮点数和整数值不能被转换为复数类型。
- 在非常量数值的转换过程中,溢出和舍入是允许的。当一个浮点数被转换为整数时,小数部分将被舍弃(向零靠拢)。
一个例子:
package main
import "fmt"
func main() {
var a, b = 1.6, -1.6 // 类型均为float64
fmt.Println(int(a), int(b)) // 1 -1
var i, j int16 = 0x7FFF, -0x8000
fmt.Println(int8(i), uint16(j)) // -1 32768
var c1 complex64 = 1 + 2i
var _ = complex128(c1)
}
8. 字符串相关的转换规则
如果一个值的类型(或者默认类型)为一个整数类型,则此值可以被当作一个码点值(rune 值)显式转换为任何字符串类型。
一个字符串可以被显式转换为一个字节切片类型��,反之亦然。 字节切片类型是指底层类型为[]byte的类型。
一个字符串可以被显式转换为一个码点切片类型,反之亦然。 码点切片类型是指底层类型为[]rune的类型。
请阅读字符串一文获取更多详情和示例。
9. 切片相关的类型转换规则
从 Go 1.17 开始,一个切片可以被转化为一个相同元素类型的数组的指针类型。 但是如果数组的长度大于被转化切片的长度,则将导致恐慌产生。
这里有一个例子。
10. 非类型安全指针相关的类型转换规则
非类型安全指针类型是指底层类型为unsafe.Pointer的类型。
任何类型安全指针类型的值可以被显式转化为一个非类型安全指针类型,反之亦然。
任何 uintptr 值可以被显式转化为一个非类型安全指针类型,反之亦然。
请阅读非类型安全指针一文获取详情和示例。
赋值规则
赋值可以看作是隐式类型转换。 各种隐式转换规则在上一节中已经列出。
除了这些规则,赋值语句中的目标值必须为一个可寻址的值、一个映射元素表达式或者一个空标识符。
在一个赋值中,源值被复制给了目标值。精确地说,源值的直接部分被复制给了目标值。
注意:函数传参和结果返回其实都是赋值。
值比较规则
Go 白皮书提到:
在任何比较中,第一个比较值必须能被赋值给第二个比较值的类型,或者反之。
所以,值比较规则和赋值规则非常相似。 换句话说,两个值是否可以比较取决于其中一个值是否可以隐式转换为另一个值的类型。 很简单?此规则描述基本正确,但是存在另外一条优先级更高的规则:
如果一个比较表达式中的两个比较值均为类型确定值,则它们的类型必须都属于可比较类型。
按照上面这条规则,如果一个不可比较类型(肯定是一个非接口类型)实现了一个接口类型,则比较这两个类型的值是非法的,即使前者的值可以隐式转化为后者。
注意,尽管切片/映射/函数类型为不可比较类型,但是它们�的值可以和类型不确定的预声明nil标识符比较。
上述规则并未覆盖所有的情况。如果两个值均为类型不确定值,它们可以比较吗?这种情况的规则比较简单:
- 两个类型不确定的布尔值可以相互比较。
- 两个类型不确定的数字值可以相互比较。
- 两个类型不确定的字符串值可以相互比较。
两个类型不确定的数字值的比较结果服从直觉。
注意,两个类型不确定的 nil 值不能相互比较。
任何比较的结果均为一个类型不确定的布尔值。
一些值比较的例子:
package main
// 一些类型为不可比较类型的变量。
var s []int
var m map[int]int
var f func()()
var t struct {x []int}
var a [5]map[int]int
func main() {
// 这些比较编译不通过。
/*
_ = s == s
_ = m == m
_ = f == f
_ = t == t
_ = a == a
_ = nil == nil
_ = s == interface{}(nil)
_ = m == interface{}(nil)
_ = f == interface{}(nil)
*/
// 这些比较编译都没问题。
_ = s == nil
_ = m == nil
_ = f == nil
_ = 123 == interface{}(nil)
_ = true == interface{}(nil)
_ = "abc" == interface{}(nil)
}
两个值是如何进行比较的?
假设两个值可以相互比较,并且它们的类型同为T。 (如果它们的类型不同,则其中一个可以转换为另一个的类型。这里我们不考虑两者均为类型不确定值的情形。)
-
如果
T是一个布尔类型,则这两个值只有在它们同为true或者false的时候比较结果才为true。 -
如果
T是一个整数类型,则这两个值只有在它们在内存中的表示完全一致的情况下比较结果才为true。 -
如果
T是一个浮点数类型, 则这两个值只要满足下面任何一种情况,它们的比较结果就为
true:
- 它们都为
+Inf; - 它们都为
-Inf; - 它们都为
-0.0或者都为+0.0。 - 它们都不是
NaN并且它们在内存中的表示完全一致。
- 它们都为
-
如果
T是一个复数类型,则这两个值只有在它们的实部和虚部均做为浮点数进行进行比较的结果都为true的情况下比较结果才为true。 -
如果
T是一个指针类型(类型安全或者非类型安全),则这两个值只有在它们所表示的地址值相等或者它们都为 nil 的情况下比较结果才为true。 -
如果
T是一个通道类型,则这两个值只有在它们引用着相同的底层内部通道或者它们都为 nil 时比较结果才为true。 -
如果
T是一个结构体类型,则它们的相应字段将逐对进行比较。只要有一对字段不相等,这两个结构体值就不相等。 -
如果
T是一个数组类型,则它们的相应元素将逐对进行比较。只要有一对元素不相等,这两个结构体值就不相等。 -
如果
T是一个接口类型,请参阅两个接口值是如何进行比较的。 -
如果
T是一个字符串类型,请参阅两个字符串值是如何进行比较的。
请注意,动态类型均为同一个不可比较类型的两个接口值的比较将产生一个恐慌。比如下面的例子:
package main
func main() {
type T struct {
a interface{}
b int
}
var x interface{} = []int{}
var y = T{a: x}
var z = [3]T{{a: y}}
// 这三个比较均会产生一个恐慌。
_ = x == x
_ = y == y
_ = z == z
}
默认参数的实现
golang 本身并不支持像 C++ 那样的函数默认参数,不过可以自己实现相关方法达到默认参数的目的;
以下用创建人的个人信息为例,名字必须输入,而邮箱地址和年龄可以不用输入,不输入时使用默认值,示例代码如下:
package main
import (
"fmt"
)
type DetailInfo struct {
Email string
Age int
}
type Handler interface {
parse(detail *DetailInfo)
}
type HandleFunc func(*DetailInfo)
func (f HandleFunc) parse(detail *DetailInfo) {
f(detail)
}
// 针对不同默认参数设置闭包函数, 这里比较关键,闭包函数=函数+运行环境(可以引用外部函数的变量)
func WithEmail(email string) HandleFunc {
return func(detail *DetailInfo) {
detail.Email = email
}
}
func WithAge(age int) HandleFunc {
return func(detail *DetailInfo) {
detail.Age = age
}
}
type Persion struct {
Name string
DetailInfo
}
// 这里的接口类Handler并不是必须的,换成闭包函数HandleFunc类型一样可以
func newPersion(name string, infos ...Handler) Persion {
detail := &DetailInfo{
Email: "unkown",
Age: -1}
for _, info := range infos {
// 接口函数调用闭包函数
info.parse(detail)
}
return Persion{Name: name, DetailInfo: DetailInfo{Email: detail.Email, Age: detail.Age}}
}
func main() {
persion1 := newPersion("小明")
fmt.Println("persion1:", persion1)
persion2 := newPersion("小红", WithEmail("xiaohong@qq.com"))
fmt.Println("persion2:", persion2)
persion3 := newPersion("张三", WithAge(18))
fmt.Println("persion3:", persion3)
persion4 := newPersion("李四", WithEmail("lisi@qq.com"), WithAge(28))
fmt.Println("persion3:", persion4)
}
输出结果:
persion1: {小明 {unkown -1}}
persion2: {小红 {xiaohong@qq.com -1}}
persion3: {张三 {unkown 18}}
persion3: {李四 {lisi@qq.com 28}}
分析:
-
关键点是用到了可变参数
...和闭包函数; -
通过可变参数循环调用闭包函数,给参数赋值;
-
通过闭包函数特性(可以引用外部函数的变量),给需要设置的参数赋值;