runtime/pprof
简介
benchmark (基准测试) 可以度量某个函数或方法的性能,也就是说,如果我们知道性能的瓶颈点在哪里,benchmark 是一个非常好的方式。但是面对一个未知的程序,如何去分析这个程序的性能,并找到瓶颈点呢?
pprof 就是用来解决这个问题的。pprof 包含两部分:
- 编译到程序中的
runtime/pprof包 - 性能剖析工具
go tool pprof
pprof 使用模式
- Report generation:报告生成
- Interactive terminal use:交互式终端
- Web interface:Web 界面
使用方法
第一种,在 go 程序中添加如下代码:
// 开启 cpu 采集分析:
pprof.StartCPUProfile(w io.Writer)
// 停止 cpu 采集分析:
pprof.StopCPUProfile()
- StartCPUProfile 为当前 process 开启 CPU profiling 。
- StopCPUProfile 停止当前的 CPU profile。当所有的 profile 写完了后它才返回。
WriteHeapProfile 把内存 heap 相关的内容写入到文件中
pprof.WriteHeapProfile(w io.Writer)
第二种,在 benchmark 测试的时候
go test -cpuprofile cpu.prof -memprofile mem.prof -bench .
第三种,对 http server 采集数据
go tool pprof $host/debug/pprof/profile
命令
go tool pprof XXX.pprof
go tool pprof 简单的使用格式为:go tool pprof [binary] [source]
- binary: 是应用的二进制文件,用来解析各种符号
- source: 表示 profile 数据的来源,可以是本地的文件,也可以是 http 地址
分析
命令行交互分析
go tool pprof XXX.pprof
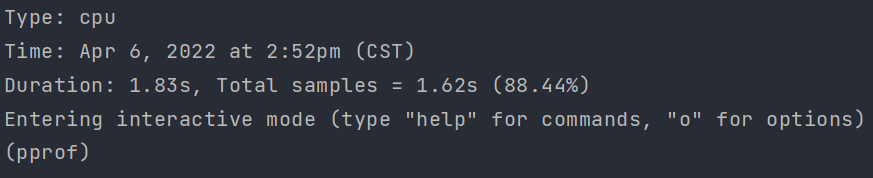
| 字段 | 说明 |
|---|---|
| Type: | 分析类型,这里是 cpu |
| Duration: | 程序执行的时长 |
Duration 下面还有一行提示,这是交互模式(通过输入 help 获取帮助信息,输入 o 获取选项信息)。
可以看出,go 的 pprof 操作还有很多其他命令。
top
top 命令:对函数的 cpu 耗时和百分比排序后输出
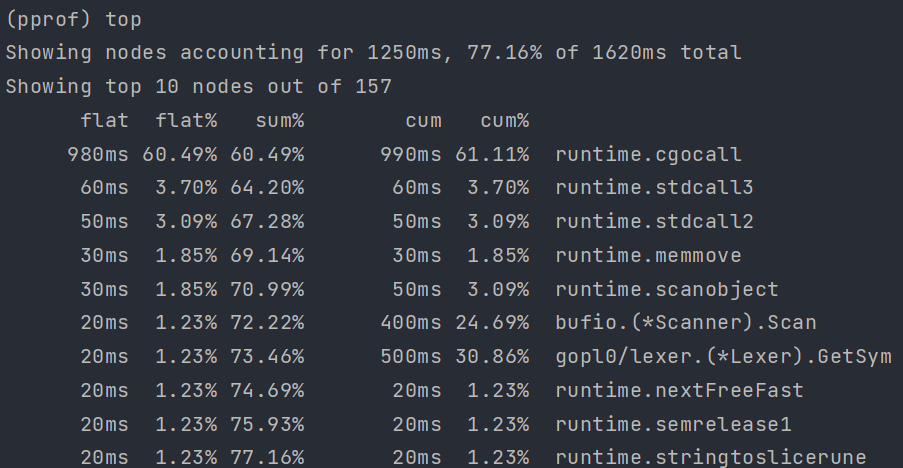
| 字段 | 说明 |
|---|---|
| flat | 当前函数占用 cpu 耗时 |
| flat % | 当前函数占用 cpu 耗时百分比 |
| sum% | 函数占用 cpu 时间累积占比,从小到大一直累积到 100% |
| cum | 当前函数加上调用当前函数的函数占用 cpu 的总耗时 |
| %cum | 当前函数加上调用当前函数的函数占用 cpu 的总耗时占比 |
可以在 top 后添加数字,如 top15
list
list 命令:可以列出函数最耗时的代码部分,格式:list 函数名

pdf
直接生成 pdf 文件
命令行下直接输出分析数据
在命令行直接输出数据,基本命令格式为:
Copygo tool pprof <format> [options] [binary] <source>
输入命令:go tool pprof -text cpu.pprof ,输出:
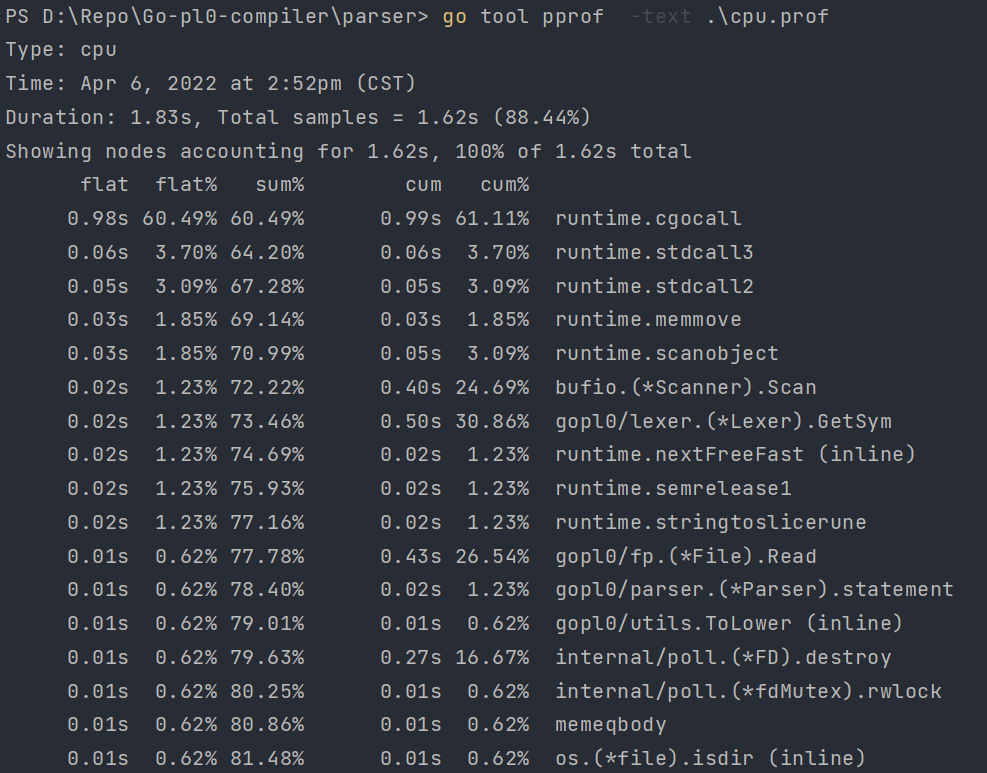
可视化分析
图形化分析前,先要安装 graphviz 软件,
- 下载地址:graphviz 地址,
下载对应的平台安装包,安装完成后,把执行文件 bin 放入 Path 环境变量中,然后在终端输入 dot -version 命令查看是否安装成功
go tool pprof -http :8080 XXX.pprof
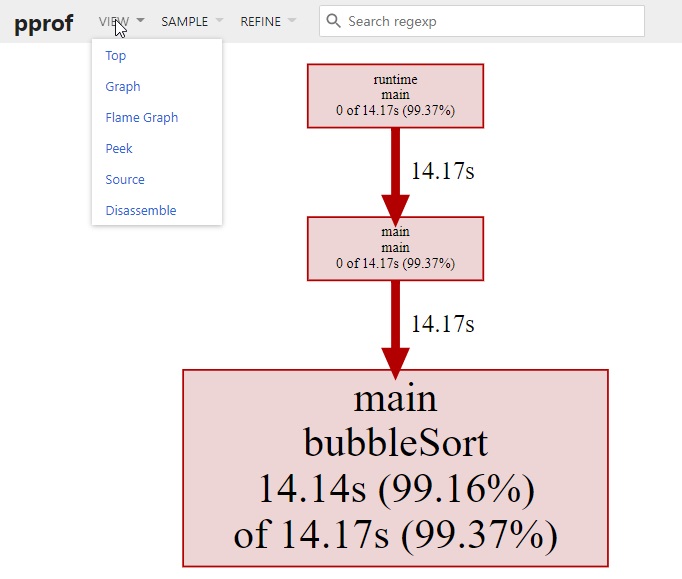
或者进入命令行交互界面输入 web 命令,即可打开一张图片
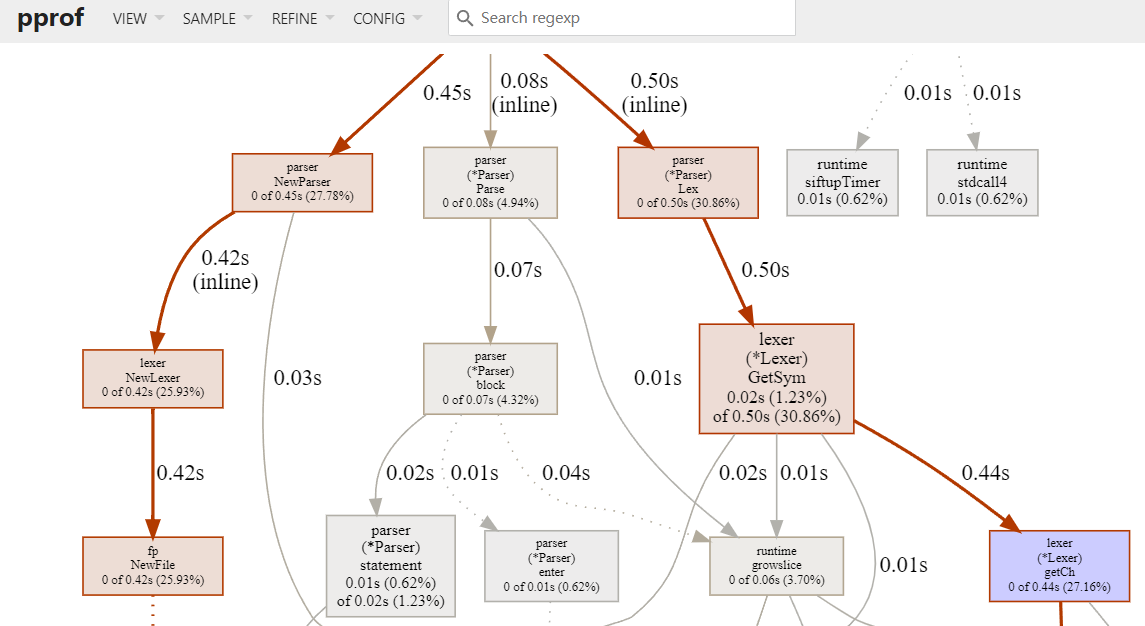
- 每个框代表一个函数,理论上框越大表示占用的 cpu 资源越多
- 每个框之间的线条代表函数之间的调用关系,线条上的数字表示函数调用的次数
- 每个框中第一行数字表示当前函数占用 cpu 的百分比,第二行数字表示当前函数累计占用 cpu 的百分比
性能分析类型
CPU 性能分析
CPU 性能分析 (CPU profiling) 是最常见的��性能分析类型。
启动 CPU 分析时,运行时 (runtime) 将每隔 10ms 中断一次,记录此时正在运行的协程 (goroutines) 的堆栈信息。
程序运行结束后,可以分析记录的数据找到最热代码路径 (hottest code paths)。
Compiler hot paths are code execution paths in the compiler in which most of the execution time is spent, and which are potentially executed very often. – What’s the meaning of “hot codepath”
一个函数在性能分析数据中出现的次数越多,说明执行该函数的代码路径 (code path) 花费的时间占总运行时间的比重越大。
内存性能分析
内存性能分析 (Memory profiling) 记录堆内存分配时的堆栈信息,忽略栈内存分配信息。
内存性能分析启用时,默认每 1000 次采样 1 次,这个比例是可以调整的。因为内存性能分析是基于采样的,因此基于内存分析数据来判断程序所有的内存使用情况是很困难的。
阻塞性能分析
阻塞性能分析 (block profiling) 是 Go 特有的。
阻塞性能分析用来记录一个协程等待一个共享资源花费的时间。在判断程序的并发瓶颈时会很有用。阻塞的场景包括:
- 在没有缓冲区的信道上发送或接收数据。
- 从空的信道上接收数据,或发送数据到满的信道上。
- 尝试获得一个已经被其他协程锁住的排它锁。
一般情况下,当所有的 CPU 和内存瓶颈解决后,才会考虑这一类分析。
锁性能分析
锁性能分析 (mutex profiling) 与阻塞分析类似,但专注于因为锁竞争导致的等待或延时。
CPU 性能分析
记录性能数据会对程序的性能产生影响,建议一次只记录一类数据。
生成 profile
Go 的运行时性能分析接口都位于 runtime/pprof 包中。只需要调用 runtime/pprof 库即可得到我们想要的数据。
假设我们实现了这么一个程序,随机生成了 5 组数据,并且使用冒泡排序法排序。
// main.go
package main
import (
"math/rand"
"time"
)
func generate(n int) []int {
rand.Seed(time.Now().UnixNano())
nums := make([]int, 0)
for i := 0; i < n; i++ {
nums = append(nums, rand.Int())
}
return nums
}
func bubbleSort(nums []int) {
for i := 0; i < len(nums); i++ {
for j := 1; j < len(nums)-i; j++ {
if nums[j] < nums[j-1] {
nums[j], nums[j-1] = nums[j-1], nums[j]
}
}
}
}
func main() {
n := 10
for i := 0; i < 5; i++ {
nums := generate(n)
bubbleSort(nums)
n *= 10
}
}
如果我们想度量这个应用程序的 CPU 性能数据,只需要在 main 函数中添加 2 行代码即可:
import (
"math/rand"
"os"
"runtime/pprof"
"time"
)
func main() {
pprof.StartCPUProfile(os.Stdout)
defer pprof.StopCPUProfile()
n := 10
for i := 0; i < 5; i++ {
nums := generate(n)
bubbleSort(nums)
n *= 10
}
}
为了简单,直接将数据输出到标准输出 os.Stdout。运行该程序,将输出定向到文件 cpu.pprof 中。
$ go run main.go > cpu.pprof
一般来说,不建议将结果直接输出到标准输出,因为如果程序本身有输出,则会相互干扰,直接记录到一个文件中是最好的方式。
func main() {
f, _ := os.OpenFile("cpu.pprof", os.O_CREATE|os.O_RDWR, 0644)
defer f.Close()
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
n := 10
for i := 0; i < 5; i++ {
nums := generate(n)
bubbleSort(nums)
n *= 10
}
}
这样只需运行 go run main.go 即可。
分析数据
接下来,可以用 go tool pprof 分析这份数据
$ go tool pprof -http=:9999 cpu.pprof
如果提示 Graphviz 没有安装,则通过 brew install graphviz(MAC) 或 apt install graphviz (Ubuntu) 即可。
访问 localhost:9999,可以看到这样的页面:
除了在网页中查看分析数据外,我们也可以在命令行中使用交互模式查看。
$ go tool pprof cpu.pprof
File: main
Type: cpu
Time: Nov 19, 2020 at 1:43am (CST)
Duration: 16.42s, Total samples = 14.26s (86.83%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 14.14s, 99.16% of 14.26s total
Dropped 34 nodes (cum <= 0.07s)
flat flat% sum% cum cum%
14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort
0 0% 99.16% 14.17s 99.37% main.main
0 0% 99.16% 14.17s 99.37% runtime.main
可以看到 main.bubbleSort 是消耗 CPU 最多的函数。
还可以按照 cum (累计消耗)排序:
(pprof) top --cum
Showing nodes accounting for 14.14s, 99.16% of 14.26s total
Dropped 34 nodes (cum <= 0.07s)
flat flat% sum% cum cum%
14.14s 99.16% 99.16% 14.17s 99.37% main.bubbleSort
0 0% 99.16% 14.17s 99.37% main.main
0 0% 99.16% 14.17s 99.37% runtime.main
help 可以查看所有支持的命令和选项:
(pprof) help
Commands:
callgrind Outputs a graph in callgrind format
comments Output all profile comments
disasm Output assembly listings annotated with samples
dot Outputs a graph in DOT format
eog Visualize graph through eog
evince Visualize graph through evince
gif Outputs a graph image in GIF format
gv Visualize graph through gv
......
内存性能分析(使用 pkg/profile)
生成 profile
假设我们实现了这么一个程序,生成长度为 N 的随机字符串,拼接在一起。
package main
import (
"github.com/pkg/profile"
"math/rand"
)
const letterBytes = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
func randomString(n int) string {
b := make([]byte, n)
for i := range b {
b[i] = letterBytes[rand.Intn(len(letterBytes))]
}
return string(b)
}
func concat(n int) string {
s := ""
for i := 0; i < n; i++ {
s += randomString(n)
}
return s
}
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
concat(100)
}
接下来,我们使用一个易用性更强的库 pkg/profile 来采集性能数据,pkg/profile 封装了 runtime/pprof 的接口,使用起来更简单。
比如我们想度量 concat() 的 CPU 性能数据,只需要一行代码即可生成 profile 文件。
import (
"github.com/pkg/profile"
)
func main() {
defer profile.Start().Stop()
concat(100)
}
运行 go run main.go:
$ go run main.go
2020/11/22 18:38:29 profile: cpu profiling enabled, /tmp/profile068616584/cpu.pprof
2020/11/22 18:39:12 profile: cpu profiling disabled, /tmp/profile068616584/cpu.pprof
CPU profile 文件已经在 tmp 目录生成,得到 profile 文件后,就可以像之前一样,用 go tool pprof 命令,在浏览器或命令行进行分析了。
接下来将使用类似的方式,进行采集内存数据,同样地,只需简单地修改 main 函数即可。
func main() {
defer profile.Start(profile.MemProfile, profile.MemProfileRate(1)).Stop()
concat(100)
}
运行 go run main.go:
$ go run main.go
2020/11/22 18:59:04 profile: memory profiling enabled (rate 1), /tmp/profile215959616/mem.pprof
2020/11/22 18:59:04 profile: memory profiling disabled, /tmp/profile215959616/mem.pprof
分析数据
接下来,我们在浏览器中分析内存性能数据:
go tool pprof -http=:9999 /tmp/profile215959616/mem.pprof

从这张图中,我们可以看到 concat 消耗了 524k 内存,randomString 仅消耗了 22k 内存。
理论上,concat 函数仅仅是将 randomString 生成的字符串拼接起来,消耗的内存应该和 randomString 一致,但怎么会产生 20 倍的差异呢?这和 Go 语言字符串内存分配的方式有关系。
字符串是不可变的,因为将两个字符串拼接时,相当于是产生新的字符串,如果当前的空间不足以容纳新的字符串,则会申请更大的空间,将新字符串完全拷贝过去,这消耗了 2 倍的内存空间。在这 100 次拼接的过程中,会产生多次字符串拷贝,从而消耗大量的内存。
那有什么好的方式呢?使用 strings.Builder 替换 + 进行字符串拼接,将有效地降低内存消耗。
func concat(n int) string {
var s strings.Builder
for i := 0; i < n; i++ {
s.WriteString(randomString(n))
}
return s.String()
}
接下来,重新运行 go run main.go:
$ go run main.go
2020/11/22 19:17:55 profile: memory profiling enabled (rate 1), /tmp/profile061547314/mem.pprof
2020/11/22 19:17:55 profile: memory profiling disabled, /tmp/profile061547314/mem.pprof
使用交互模式,查看内存消耗情况:
$ go tool pprof /tmp/profile061547314/mem.pprof
File: main
Type: inuse_space
Time: Nov 22, 2020 at 7:17pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top --cum
Showing nodes accounting for 71.22kB, 89.01% of 80.01kB total
Dropped 25 nodes (cum <= 0.40kB)
Showing top 10 nodes out of 50
flat flat% sum% cum cum%
0 0% 0% 71.88kB 89.84% main.main
0 0% 0% 71.88kB 89.84% runtime.main
0 0% 0% 67.64kB 84.54% main.concat
45.77kB 57.20% 57.20% 45.77kB 57.20% strings.(*Builder).WriteString
21.88kB 27.34% 84.54% 21.88kB 27.34% main.randomString
可以看到,使用 strings.Builder 后,concat 内存消耗降为了原来的 1/8 。
benchmark 生成 profile
除了直接在命令行中查看测试的结果外,也可以生成 profile 文件,使用 go tool pprof 分析。
testing 支持生成 CPU、memory 和 block 的 profile 文件。
-cpuprofile=$FILE-memprofile=$FILE,-memprofilerate=N调整记录速率为原来的 1/N。-blockprofile=$FILE
在介绍 benchmark 如何使用,我们举了下面这个例子:
func fib(n int) int {
if n == 0 || n == 1 {
return n
}
return fib(n-2) + fib(n-1)
}
func BenchmarkFib(b *testing.B) {
for n := 0; n < b.N; n++ {
fib(30) // run fib(30) b.N times
}
}
只需要在 go test 添加 -cpuprofile 参数即可生成 BenchmarkFib 对应的 CPU profile 文件:
$ go test -cpuprofile cpu.prof -memprofile mem.prof -bench .
goos: linux
goarch: amd64
pkg: example
BenchmarkFib-8 196 6071636 ns/op
PASS
ok example 2.046s
用例执行完毕后,当前目录多出了一个 cpu.pprof 文件,接下来就可以使用 go tool pprof 命令进行分析了。
使用 -text 选项可以直接将结果以文本形式打印出来。
$ go tool pprof -text cpu.pprof
File: example.test
Type: cpu
Time: Nov 22, 2020 at 7:52pm (CST)
Duration: 2.01s, Total samples = 1.77s (87.96%)
Showing nodes accounting for 1.77s, 100% of 1.77s total
flat flat% sum% cum cum%
1.76s 99.44% 99.44% 1.76s 99.44% example.fib
0.01s 0.56% 100% 0.01s 0.56% runtime.futex
0 0% 100% 1.76s 99.44% example.BenchmarkFib
0 0% 100% 0.01s 0.56% runtime.findrunnable
pprof 支持多种输出格式(图片、文本、Web 等),直接在命令行中运行 go tool pprof 即可看到所有支持的选项:
$ go tool pprof
Details:
Output formats (select at most one):
-dot Outputs a graph in DOT format
-png Outputs a graph image in PNG format
-text Outputs top entries in text form
-tree Outputs a text rendering of call graph
-web Visualize graph through web browser
...