索引
概述
索引支持 MongoDB 中查询的高效执行。如果没有索引,MongoDB 必须扫描集合中的每个文档才能返回查询结果。如果查询存在适当的索引,MongoDB 会使用该索引来限制必须扫描的文档数量。
虽然索引可以提高查询性能,但添加索引会对写入操作的性能产生负面影响。对于具有高写入读取比率的集合,索引的成本很高,因为每次插入还必须更新任何索引。
场景
如果您的应用程序在相同字段上重复运行查询,您可以在这些字段上创建索引以提高性能。例如,考虑以下场景:
| 设想 | 指数类型 |
|---|---|
| 人力资源部门经常需要通过员工 ID 查找员工。您可以在员工 ID 字段上创建索引以提高查询性能。 | 单字段索引 |
销售人员经常需要按位置查找客户信息。位置存储在带有 state、city 和 等字段的嵌入对象中 zipcode。您可以在整个对象上创建索引 location,以提高对该对象中任何字段的查询性能。 | 对象上的 单字段索引 |
杂货店经理经常需要按名称和数量查找库存物品,以确定哪些物品库存不足。item 您可以在和字段上创建单个索引 quantity 以提高查询性能。 | 复合索引 |
细节
- 索引是一种特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。MongoDB 索引使用 B树 数据结构
- 索引条目的排序支持高效的相等匹配和基于范围的查询操作;故可以使用索引中的排序返回排序结果
- MongoDB 在创建集合期间在
_id字段上创建唯一索引。该索引可防止客户端插入两个具有相同字段值的文档。您不能删除该索引 - 索引的默认名称是索引键和索引中每个键的方向(
1或-1)的串联,使用下划线作为分隔符。例如,创建的索引的{ item : 1, quantity: -1 }名称为item_1_quantity_-1 - 索引一旦创建就无法重命名,只能删掉重新加
创建索引
使用 db.collection.createIndex()
db.collection.createIndex( <key and index type specification>, <options> )
例子
db.collection.createIndex( { name: -1 } )
对于单字段索引,索引键的排序顺序(升序或降序)并不重要,因为 MongoDB 可以沿任一方向遍历索引
获取索引
db.collection.getIndexes()
上个例子会输出:
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{ v: 2, key: { name: -1 }, name: 'name_-1' }
]
指定索引名称
db.<collection>.createIndex(
{ <field>: <value> },
{ name: "<indexName>" }
)
- 索引名称必须是唯一的。使用现有索引的名称创建索引会返回错误。
- 无法重命名现有索引,必须 删除 索引并使用新名称重新创建索引。
如果创建索引时不指定名称,系统将通过将每个索引键字段和值用下划线连接来生成名称。例如:
| 索引 | 默认名称 |
|---|---|
{ score : 1 } | score_1 |
{ content : "text", "description.tags": "text" } | content_text_description.tags_text |
{ category : 1, locale : "2dsphere"} | category_1_locale_2dsphere |
{ "fieldA" : 1, "fieldB" : "hashed", "fieldC" : -1 } | fieldA_1_fieldB_hashed_fieldC_-1 |
删除索引
要删除索引,请使用以下 shell 方法之一:
| 方法 | 描述 |
|---|---|
db.collection.dropIndex() | 从集合中删除特定索引 |
db.collection.dropIndexes() | 从集合或索引数组中删除所有可移动索引(如果指定) |
您可以删除字段上除默认索引之外的任何索引 _id。要删除 _id 索引,您必须删除整个集合。
如果删除生产中积极使用的索引,则可能会遇到性能下降的情况。在删除索引之前,请考虑 隐藏该索引 以评估删除的潜在影响。
要删除索引,您需要它的名称。要获取集合的所有索引名称,请运行 getIndexes()
db.<collection>.getIndexes()
删除索引后,系统会返回有关操作状态的信息。
输出示例:
...
{ "nIndexesWas" : 3, "ok" : 1 }
...
nIndexesWas 反映了删除索引之前的索引数量
删除单个索引
要删除特定索引,请使用该 dropIndex() 方法并指定索引名称:
db.<collection>.dropIndex("<indexName>")
删除多个索引
要删除多个索引,请使用该 dropIndexes() 方法并指定索引名称数组:
db.<collection>.dropIndexes("<index1>", "<index2>", "<index3>")
删除除 _id 索引之外的所有索引
要删除除 _id 索引之外的所有索引,dropIndexes() 中不指定索引名称即可:
db.<collection>.dropIndexes()
管理索引
列出集合上的所有索引
要返回一个集合上的所有索引的列表,使用 db.collection.getIndexes()
例如,要查看 people 集合上的所有索引,请运行以下命令:
db.people.getIndexes()
列出数据库的所有索引
要列出数据库中的所有集合索引,请在 mongosh 中运行如下命令:
db.getCollectionNames().forEach(function(collection) {
indexes = db[collection].getIndexes();
print("Indexes for " + collection + ":");
printjson(indexes);
});
列出特定类型的索引
要列出所有数据库中所有集合的某一类型(如哈希或文本)的所有索引,请在 mongosh 中运行以下命令:
// The following finds all hashed indexes
db.adminCommand("listDatabases").databases.forEach(function(d){
let mdb = db.getSiblingDB(d.name);
mdb.getCollectionInfos({ type: "collection" }).forEach(function(c){
let currentCollection = mdb.getCollection(c.name);
currentCollection.getIndexes().forEach(function(idx){
let idxValues = Object.values(Object.assign({}, idx.key));
if (idxValues.includes("hashed")) {
print("Hashed index: " + idx.name + " on " + d.name + "." + c.name);
printjson(idx);
};
});
});
});
索引类型
单字段索引
单字段索引收集集合中每个文档中单个字段的数据并对其进行排序。
此图显示了单个字段上的索引 score:
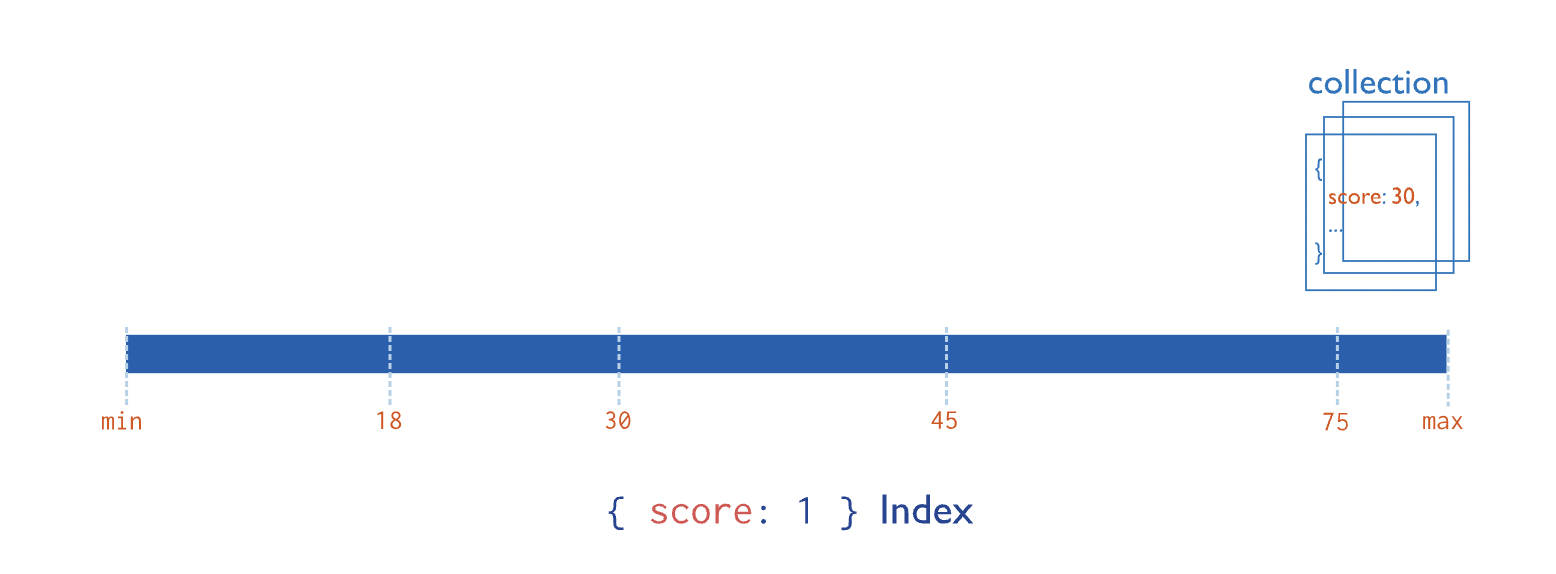
可以在文档中的任何字段上创建单字段索引,包括:
- 顶级文档字段
- 嵌入文档
- 嵌入文档中的字段
创建索引时,需要指定:
- 字段名
- 索引值的排序顺序(升序或降序)
1升序、-1降序
db.<collection>.createIndex( { <field>: <sortOrder> } )
示例
创建 students 包含以下文档的集合:
db.students.insertMany( [
{
"name": "Alice",
"gpa": 3.6,
"location": { city: "Sacramento", state: "California" }
},
{
"name": "Bob",
"gpa": 3.2,
"location": { city: "Albany", state: "New York" }
}
] )
在单个字段上创建索引
假设有一位经常通过 GPA 来查找学生的学校管理人员。您可以在字段上创建索引 gpa 以提高这些查询的性能:
db.students.createIndex( { gpa: 1 } )
该索引支持对字段进行选择的查询 gpa,如下所示:
db.students.find( { gpa: 3.6 } )
db.students.find( { gpa: { $lt: 3.4 } } )
在嵌入文档上创建索引
您可以对整个嵌入文档创建索引。
考虑一个社交网络应用程序,学生可以在其中按位置搜索彼此。学生位置存储在名为 的嵌入式文档中 location。该 location 文档包含字段 city 和 state。
您可以在字段上创建索引 location 以提高文档查询的性能 location:
db.students.createIndex( { location: 1 } )
以下查询使用字段上的索引 location:
db.students.find( { location: { city: "Sacramento", state: "California" } } )
当您基于嵌入文档进行查询时,指定字段的顺序很重要。查询中嵌入的文档和返回的文档必须完全匹配。
当您在嵌入文档上创建索引时,只有指定整个嵌入文档的查询才会使用该索引。对文档中特定字段的查询不使用索引。
例如,以下查询不使用字段上的索引 location,因为它们仅指定了嵌入文档中的特定字段:
db.students.find( { "location.city": "Sacramento" } )
db.students.find( { "location.state": "New York" } )
在嵌入字段上创建索引
您可以在嵌入文档中的字段上创建索引。嵌入字段上的索引可以满足使用 点表示法的查询。
该 location 字段是一个嵌入文档,包含嵌入字段 city 和 state。在字段上创建索引 location.state:
db.students.createIndex( { "location.state": 1 } )
索引支持对字段进行查询 location.state,例如:
db.students.find( { "location.state": "California" } )
db.students.find( { "location.city": "Albany", "location.state": "New York" } )
复合索引 Compound Indexes
定义:引用多个字段的索引
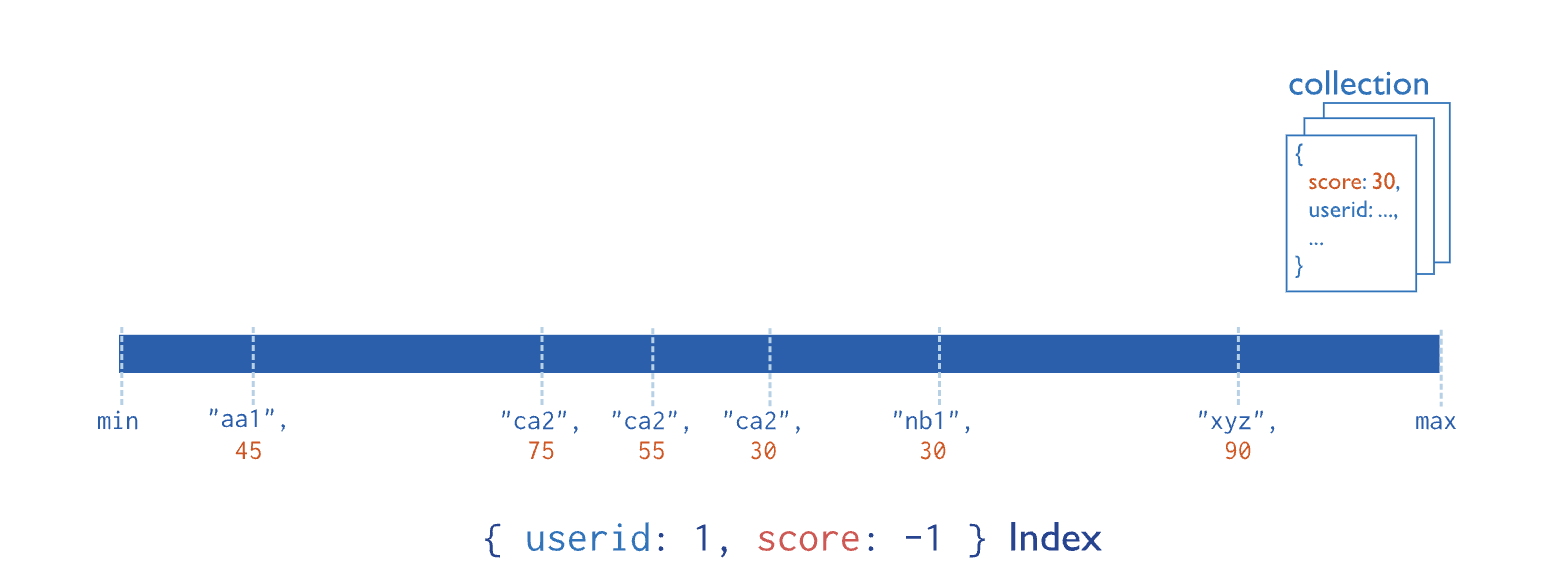
复合索引的数据按索引中的第一个字段分组,然后按每个后续字段分组。
- 例如,下图显示了一个复合索引,其中文档首先按
userid升序(字母序)分组。然后,按scores降序排序:
要创建复合索引,请使用以下原型:
db.<collection>.createIndex( {
<field1>: <sortOrder>,
<field2>: <sortOrder>,
...
<fieldN>: <sortOrder>
} )
ESR(相等、排序、范围)规则
https://www.mongodb.com/zh-cn/docs/v7.0/tutorial/equality-sort-range-rule/
要强制 MongoDB 使用特定索引,请在测试索引时使用 cursor.hint()
索引字段的顺序会影响复合索引的有效性
equal
相等指单个值的精确匹配(exact match)
- 以下精确匹配查询扫描
cars集合以查找model字段Cordoba精确匹配的文档。
db.cars.find( { model: "Cordoba" } )
db.cars.find( { model: { $eq: "Cordoba" } } )
索引搜索可高效利用精确匹配来限制为完成某一查询而需检查的文档数量。故优先放置需要精确匹配的字段。
一个索引可能有多个用于精确匹配的键。用于等值匹配的索引键可以以任何顺序出现。但是,如要使用索引满足等值匹配,所有用于精确匹配的索引键必须放在其他索引字段之前。MongoDB 的搜索算法让您无需以特定顺序排列精确匹配字段。
精确匹配应具有选择性,即只匹配少数文档。为了减少扫描的索引键数量,请在等值匹配的测试中确保判断条件能筛选掉至少 90% 的文档。
sort
排序决定结果的顺序。排序操作在等值匹配之后,因为等值匹配会减少需要排序的文档数量。在等值匹配之后进行排序还能让 MongoDB 进行非阻塞排序。
当查询字段是索引键的子集时,索引可以支持排序操作。仅当查询包含排序键之前的所有前缀键的相等条件时,才支持对索引键子集进行排序操作。
- 以下示例将查询
cars集合。输出将按model进行排序:
db.cars.find( { manufacturer: "GM" } ).sort( { model: 1 } )
- 要提高查询性能,请对
manufacturer和model字段创建索引:
db.cars.createIndex( { manufacturer: 1, model: 1 } )
manufacturer是第一个键,因为它是相等匹配。- 按照与查询相同的顺序 (
model) 为1创建索引。
range
范围过滤器会扫描字段。此扫描不要求精确匹配,因此范围过滤器会松散绑定到索引键。为提高查询效率,应尽可能缩小范围边界,并使用等值匹配来限制必须扫描的文档数量。
范围筛选器类似如下内容:
db.cars.find( { price: { $gte: 15000} } )
db.cars.find( { age: { $lt: 10 } } )
db.cars.find( { priorAccidents: { $ne: null } } )
MongoDB 无法对范围过滤器的结果进行索引排序。将范围过滤器置于排序谓词之后,以便 MongoDB 可使用非阻塞索引排序。
例子
以下查询在 cars 集合中搜索福特制造的价格超过 15,000 美元的车辆。结果按车型排序:
db.cars.find(
{
manufacturer: 'Ford',
cost: { $gt: 15000 }
} ).sort( { model: 1 } )
该查询包含了 ESR 规则中的所有元素:
manufacturer: 'Ford'是基于相等的匹配操作cost: { $gt: 15000 }为基于范围的匹配操作,并且model用于排序
根据 ESR 规则,对于该示例查询,最优的索引为:
{ manufacturer: 1, model: 1, cost: 1 }
其他
- 不等式操作符,如
$ne或$nin是范围操作符,而不是相等操作符。 $regex是一个范围操作符。$in:$in单独使用时,它是一个执行一系列相等匹配的相等运算符。- 当
$in与.sort()一起使用时:- 如果
$in的数组元素少于 200,则这些元素将展开,然后按照为索引指定的排序顺序进行合并。这会提高小型数组的性能。$in类似于具有 ESR 的相等谓词。 - 如果
$in具有 200 个或更多元素,则这些元素的排序方式类似于范围操作符。在这种情况下,小型数组没有实现性能提升。索引中的后续字段无法提供排序,并且$in类似于具有 ESR 的范围谓词。 - 如果通常将
$ins用于小型数组,请在索引规范的前面位置包含$ins。如果通常使用大型数组,请在包含范围谓词的位置包含$ins。
- 如果
细节
- 单个复合索引的字段数量上限是 32 个
- 在 MongoDB 4.4 及更高版本中,复合索引可能包含单个 哈希索引字段。
- 在 MongoDB 4.2 及更早版本中,复合索引不能包含任何哈希索引字段。
索引前缀
索引前缀是索引字段的开始子集。复合索引支持对索引前缀中包含��的所有字段进行查询。
例如,考虑这个复合索引:
{ "item": 1, "location": 1, "stock": 1 }
该索引具有以下索引前缀:
{ item: 1 }{ item: 1, location: 1 }
MongoDB 可以使用复合索引来支持对这些字段组合的查询:
itemitem和locationitem,location, 和stockitem和stock(mongodb 独有的特性)- 此时
item字段对应于前缀。 - 但是,在支持查询方面,索引的效率不如只支持
item和stock的索引。
- 此时
索引字段按顺序解析;如果查询省略索引前缀,则无法使用该前缀后面的任何索引字段。
MongoDB无法使用复合索引来支持这些字段组合的�查询:
locationstocklocation和stock
如果没有该 item 字段,则前面的字段组合都不对应前缀索引。
提示:删除冗余索引
如果您的集合同时具有复合索引和前缀索引(例如
{ a: 1, b: 1 }和{ a: 1 }),并且两个索引都没有 稀疏 或 唯一 约束,则可以删除前缀 ({ a: 1 }) 上的索引。MongoDB 在所有需要使用前缀索引的情况下都使用复合索引。
稀疏复合索引
复合索引可以包含不同类型的稀疏索引。索引类型的组合决定了复合索引如何匹配文档。
下表总结了包含不同类型稀疏索引的复合索引的行为:
| 复合索引组件 | 复合索引的行为 |
|---|---|
| 升序指数降序索引 | 仅索引至少包含一个键的值的文档。 |
| 升序指数降序索引 地理空间索引 | 仅当文档包含某个字段的值时才索引该文档 geospatial。不按升序或降序索引��对文档进行索引。 |
| 升序指数降序索引 文本索引 | 仅当文档与其中一个 text 字段匹配时才索引该文档。不按升序或降序索引对文档进行索引。 |
排序顺序支持
若要查询:
db.leaderboard.find().sort( { score: -1, username: 1 } )
以下索引提高了排行榜结果的性能,因为索引的排序顺序与查询中使用的排序顺序相匹配:
db.leaderboard.createIndex( { score: -1, username: 1 } )
db.leaderboard.find().sort( { score: 1, username: -1 } ) # MongoDB 可以在任一方向遍历复合索引。
复合索引不支持排序顺序与索引不匹配或与索引相反的查询。例如以下查询:
db.leaderboard.find().sort( { score: 1, username: 1 } )
db.leaderboard.find().sort( { score: -1, username: -1 } )
此外,对于使用索引的排序操作,排序中指定的字段的出现顺序必须与它们在索引中出现的顺序相同。因此,上述索引无法支持此查询:
db.leaderboard.find().sort( { username: 1, score: -1, } )
示例
如果您的应用程序重�复运行包含多个字段的查询,您可以创建复合索引来提高该查询的性能。例如,杂货店经理经常需要按名称和数量查找库存物品,以确定哪些物品库存不足。item 您可以在和 字段上创建复合索引 quantity 以提高查询性能。
name 以下操作创建包含和字段的复合索引 gpa:
db.students.createIndex( {
name: 1,
gpa: -1
} )
创建的索引支持选择以下项的查询:
- 两者
name和gpa领域。 - 只有
name字段,因为name是复合索引的 前缀。
例如,索引支持以下查询:
db.students.find( { name: "Alice", gpa: 3.6 } )
db.students.find( { name: "Bob" } )
该索引不支持仅对 gpa 字段进行查询,因为 gpa 该字段不是索引前缀的一部分。例如,索引不支持以下查询:
db.students.find( { gpa: { $gt: 3.5 } } )
多键索引 Multikey Indexes
多键索引收集并排序存储在数组中的数据。
您不需要显式指定多键类型。当您在包含数组值的字段上创建索引时,MongoDB 会自动将该索引设置为多键索引。
此图显示了字段上的多键索引 addr.zip:

MongoDB 可以在包含标量值(例如字符串和数字)和嵌入文档的数组上创建多键索引。
如果您的应用程序频繁查询包含数组值的字段,则多键索引可提高这些查询的性能。
要创建多键索引,请使用以下原型:
db.<collection>.createIndex( { <arrayField>: <sortOrder> } )
细节
- 索引扫描的范围定义了查询期间要搜索的索引部分。多键索引边界的计算遵循特殊规则
- 在 唯一 多键索引中,文档可能具有导致重复索引键值的数组元素,只要该文档的索引键值不与另一个文档的索引键值重复即可
- 散列索引不能是多键的
$expr运算符不支持多键索引
复合多键索引
在复合多键索引中,每个索引文档最多可以有一个数组字段。具体来说:
-
如果索引规范中多个字段是数组,则无法创建复合多键索引。例如,考虑包含此文档的集合:
{ _id: 1, scores_spring: [ 8, 6 ], scores_fall: [ 5, 9 ] }您无法创建复合多键索引,
{ scores_spring: 1, scores_fall: 1 }因为索引中的两个字段都是数组。 -
如果复合多键索引已存在,则无法插入违反此限制的文档。
考虑包含以下文档的集合:
{ _id: 1, scores_spring: [8, 6], scores_fall: 9 }
{ _id: 2, scores_spring: 6, scores_fall: [5, 7] }您可以创建复合多键索引
{ scores_spring: 1, scores_fall: 1 },因为对于每个文档,只有一个由复合多键索引索引的字段是数组。没有文档同时包含scores_spring和scores_fall字段的数组值。但是,在创建复合多键索引后,如果尝试插入
scores_spring和scores_fall字段均为数组的文档,则插入会失败。
查询整个数组字段
当查询过滤器指定 整个数组的精确匹配 时,MongoDB 可以使用多键索引来查找查询数组的第一个元素,但不能使用多键索引扫描来查找整个数组。
相反,在使用多键索引查找查询数组的第一个元素后,MongoDB 会检索关联文档并筛选其数组与查询中的数组匹配的文档。
例如,考虑 inventory 包含以下文档的集合:
db.inventory.insertMany( [
{ _id: 5, type: "food", item: "apple", ratings: [ 5, 8, 9 ] }
{ _id: 6, type: "food", item: "banana", ratings: [ 5, 9 ] }
{ _id: 7, type: "food", item: "chocolate", ratings: [ 9, 5, 8 ] }
{ _id: 8, type: "food", item: "fish", ratings: [ 9, 5 ] }
{ _id: 9, type: "food", item: "grapes", ratings: [ 5, 9, 5 ] }
] )
db.inventory.createIndex( { ratings: 1 } )
以下查询查找字段为 ratings 数组的文档 [ 5, 9 ]:
db.inventory.find( { ratings: [ 5, 9 ] } )
MongoDB 可以使用多键索引来查找数组 5 中任意位置的文档 ratings。ratings 然后,MongoDB 检索这些文档并过滤数组等于查询数组的文档 [ 5, 9 ]。
示例
在数组字段上创建
示例使用 students 包含以下文档的集合:
db.students.insertMany( [
{
"name": "Andre Robinson",
"test_scores": [ 88, 97 ]
},
{
"name": "Wei Zhang",
"test_scores": [ 62, 73 ]
},
{
"name": "Jacob Meyer",
"test_scores": [ 92, 89 ]
}
] )
例如,students 集合中的文档包含一个 test_scores 字段:学生在整个学期收到的考试成绩的数组。您定期更新尖子生列表:至少有 5 个 test_scores 大于 的学生 90。
以下操作在 集合 test_scores 的字段上创建升序多键索引 students:
db.students.createIndex( { test_scores: 1 } )
由于 test_scores 包含数组值,MongoDB 将此索引存储为多键索引。
结果:该索引包含字段中出现的每个单独值的键 test_scores。索引是升序的,这意味着键按以下顺序存储:[ 62, 73, 88, 89, 92, 97 ]。
索引支持对字段进行选择的查询 test_scores。例如,以下查询返回数组中至少有一个元素 test_scores 大于 90 的文档:
db.students.find(
{
test_scores: { $elemMatch: { $gt: 90 } }
}
)
输出:
[
{
_id: ObjectId("632240a20646eaee87a56a80"),
name: 'Andre Robinson',
test_scores: [ 88, 97 ]
},
{
_id: ObjectId("632240a20646eaee87a56a82"),
name: 'Jacob Meyer',
test_scores: [ 92, 89 ]
}
在数组的嵌入字段上创建
考虑此结构的集合:
db.inventory.insertMany( [
{
"item": "t-shirt",
"stock": [
{
"size": "small",
"quantity": 8
},
{
"size": "large",
"quantity": 10
},
]
},
{
"item": "sweater",
"stock": [
{
"size": "small",
"quantity": 4
},
{
"size": "large",
"quantity": 7
},
]
},
{
"item": "vest",
"stock": [
{
"size": "small",
"quantity": 6
},
{
"size": "large",
"quantity": 1
}
]
}
] )
在 集合 stock.quantity 的字段上创建升序多键索引 inventory:
db.inventory.createIndex( { "stock.quantity": 1 } )
由于 stock 包含数组值,MongoDB 将此索引存储为多键索引。
该索引包含字段中出现的每个单独值的键 stock.quantity。索引是升序的,这意味着键按以下顺序存储:[ 1, 4, 6, 7, 8, 10 ]。
以下查询返回数组中至少stock 有一个元素 quantity 小于 5 的文档:
db.inventory.find(
{
"stock.quantity": { $lt: 5 }
}
)
输出:
[
{
_id: ObjectId("63449793b1fac2ee2e957ef3"),
item: 'vest',
stock: [ { size: 'small', quantity: 6 }, { size: 'large', quantity: 1 } ]
},
{
_id: ObjectId("63449793b1fac2ee2e957ef2"),
item: 'sweater',
stock: [ { size: 'small', quantity: 4 }, { size: 'large', quantity: 7 } ]
}
]
索引还支持对字段进行排序操作 stock.quantity,比如这个查询:
db.inventory.find().sort( { "stock.quantity": -1 } )
输出:
[
{
_id: ObjectId("63449793b1fac2ee2e957ef1"),
item: 't-shirt',
stock: [ { size: 'small', quantity: 8 }, { size: 'large', quantity: 10 } ]
},
{
_id: ObjectId("63449793b1fac2ee2e957ef2"),
item: 'sweater',
stock: [ { size: 'small', quantity: 4 }, { size: 'large', quantity: 7 } ]
},
{
_id: ObjectId("63449793b1fac2ee2e957ef3"),
item: 'vest',
stock: [ { size: 'small', quantity: 6 }, { size: 'large', quantity: 1 } ]
}
]
当对对象数组进行降序排序时,MongoDB 首先根据具有最高值元素的字段进行排序。
地理空间索引
地理空间索引可提高地理空间坐标数据查询的性能
MongoDB 提供两种类型的地理空间索引:
- 使用平面几何返回结果的 二维索引
- 使用球面几何形状返回结果的 2dsphere 索引
文本索引
文本索引支持对包含字符串内容的字段进行文本搜索查询。
文本索引可提高在字符串内容中搜索特定单词或短语时的性能。
一个集合只能有一个文本索引,但该索引可以涵盖多个字段。
db.<collection>.createIndex(
{
<field1>: "text",
<field2>: "text",
...
}
)
存储要求和性能成本
- 文本索引可能占用大量内存。对于每个插入的文档,在每个索引字段中的每个唯一的词的后处理词形都包含一个索引条目。
- 构建文本索引类似于构建大型的 多键索引,但比在相同数据上构建简单有序(标量)索引需要更长时间。
- 在构建占用大量内存的文本索引时,确保您的文件描述符拥有足够高的限制。
- 文本索引会影响��写入性能,因为 MongoDB 必须为每个新的源文档的每个索引字段中的每个唯一的词添加一个索引条目。
- 文本索引存储文本字符串的单个单词,而不存储短语或有关文档中单词之间距离的信息。因此,如果整个集合适合在 RAM 中,指定多个词的查询会更快执行。
详情请参考:https://docs.whaleal.com/mongodb-manual-zh/docs/08-indexes/03-Index-Types/04-Text-Indexes
哈希索引
哈希索引支持 哈希分片。散列索引对字段值的散列进行索引。
聚集索引
5.3 版本中的新功能
聚集索引指定聚集集合 存储数据的顺序。使用聚集索引创建的集合称为聚集集合
通配符索引 Wildcard Indexes
使用通配符索引支持对任意或未知字段的查询。
db.collection.createIndex( { "$**": <sortOrder> } )
- 仅当您要索引的字段未知或可能更改时才使用通配符索引。通配符索引在特定字段上的性能不如目标索引。
- 如果您的应用程序查询字段名称因文档而异的集合,请创建通配符索引以支持对所有可能的文档字段名称的查询。
- 如果您的应用程序重复查询子字段不一致的嵌入文档字段,请创建通配符索引以支持对所有子字段的查询。
- 如果您的应用程序查询具有共同特征的文档。复合通配符索引可以有效地覆盖对具有公共字段的文档的许多查询。
索引属性
唯一索引
唯一索引确保索引字段不存储重复;即强制索引字段的唯一性。
db.collection.createIndex( <key and index type specification>, { unique: true } )
您还可以对复合索引强制执行唯一约束。字段组合的唯一性会被保证,如:
db.members.createIndex( { groupNumber: 1, lastname: 1, firstname: 1 }, { unique: true } )
groupNumber、lastname 和 firstname 的组合必须是唯一的。
细节
- 不能在已经包含重复值的字段上创建唯一索引。
- 如果文档在唯一索引中没有索引字段的值,则索引将为该文档存储空值。由于唯一性约束,MongoDB 只允许一个缺少索引字段的文档。如果有多个文档没有索引字段值或缺少索引字段,则索引构建将失败并出现重复键错误。
- 类似:E11000 duplicate key error index: test.collection.$a.b_1 dup key: { : null }
稀疏索引
稀疏索引只包含具有索引字段的文档的条目,即使索引字段为空。
稀疏索引会跳过任何缺少索引字段的文档。
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )
细节
- 如果稀疏索引会导致查询和排序操作的结果集不完整,MongoDB 将不会使用该索引,除非显式
hint()指定该索引。- 例如,除非明确提示,否则查询
{ x: { $exists: false } }不会在字段上使用稀疏索引。
- 例如,除非明确提示,否则查询
- 以下索引类型始终是稀疏的:2d、2dsphere(版本 2)、文本、通配符
- 同时具有稀疏属性和唯一属性的索引,可以防止集合中的文档在某个字段上具有重复的值,但允许多个文档省略该字段。
部分索引
部分索引仅对集合中满足指定过滤表达式的文档进行索引。通过对集合中的文档子集建立索引,部分索引具有较低的存储要求,并降低了索引创建和维护的性能成本。
使用 partialFilterExpression 选项来创建部分索引,支持:
- 等式表达式(即
field: value或使用$eq运算符), $exists: true表达,$gt,$gte,$lt,$lte表达式,$type表达式,$and操作员,$or操作员,$in操作员
例如,以下操作创建一个索引,仅对字段 rating 大于 5 的文档建立索引。
db.restaurants.createIndex(
{ cuisine: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)
查询覆盖率
如果使用部分索引导致结果集不完整,MongoDB 不会使用部分索引进行查询或排序操作。
要使用部分索引,查询必须包含过滤表达式(或指定过滤表达式子集的修改过滤表达式)作为其查询条件的一部分。
对于上个例子来说,rating: { $gte: 8 } 是可以触发部分索引的:
db.restaurants.find( { cuisine: "Italian", rating: { $gte: 8 } } )
但是,以下查询无法在字段上使用部分索引:
db.restaurants.find( { cuisine: "Italian", rating: { $lt: 8 } } )
db.restaurants.find( { cuisine: "Italian" } )
细节
- 部分索引应该优先于稀疏索引。部分索引具有以下优点:
- 更好地控制哪些文档被索引。
- 是稀疏索引提供的功能的超集。
TTL 索引
TTL 索引是特殊的单字段索引,MongoDB 可以使用它在一段时间后或在特定时钟时间自动从集合中删除文档。
数据过期对于某些类型的信息非常有用,例如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保留有限的时间。
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
expireAfterSeconds 的值必须在 0 和 2147483647 之间
将非 TTL 单字段索引转换为 TTL 索引
从 MongoDB 5.1 开始,您可以将该 expireAfterSeconds 选项添加到现有的单字段索引。要将非 TTL 单字段索引更改为 TTL 索引,请使用 collMod 数据库命令:
db.runCommand({
"collMod": <collName>,
"index": {
"keyPattern": <keyPattern>,
"expireAfterSeconds": <number>
}
})
以下示例将具有模式的非 TTL 单字段索引转换 { "lastModifiedDate": 1 } 为 TTL 索引:
db.runCommand({
"collMod": "tickets",
"index": {
"keyPattern": { "lastModifiedDate": 1 },
"expireAfterSeconds": 100
}
})
更改 expireAfterSecondsTTL 索引的值
要更改 expireAfterSecondsTTL 索引的值,还是使用 collMod 就好了
db.runCommand({
"collMod": <collName>,
"index": {
"keyPattern": <keyPattern>,
"expireAfterSeconds": <number>
}
})
以下示例使用集合上的 expireAfterSeconds 模式更改索引的值 :{ "lastModifiedDate": 1 }``tickets
db.runCommand({
"collMod": "tickets",
"index": {
"keyPattern": { "lastModifiedDate": 1 },
"expireAfterSeconds": 100
}
})
细节
- TTL 索引在自索引字段值经过指定秒数后使文档过期;即过期阈值是索引字段值加上指定的秒数
- 如果文档中的索引字段不是日期或日期数组,则该文档不会过期
- 后台线程
mongod读取索引中的值并从集合中删除过期的文档 - TTL 索引与非 TTL 索引��的查询方式是相同的
- TTL 索引是单字段索引。复合索引不支持 TTL 并忽略该 expireAfterSeconds 选项。
_id字段不支持 TTL 索引
隐藏索引
隐藏索引对查询计划程序不可见,并且不能用于支持查询。
通过向规划者隐藏索引,用户可以评估删除索引的潜在影响,而无需实际删除索引。如果影响是负面的,用户可以取消隐藏索引,而不必重新创建已删除的索引。
将 hidden 选项设置为 true 来隐藏索引
例如,以下操作将在 borough 字段上创建隐藏的升序索引:
db.addresses.createIndex(
{ borough: 1, ratings: 1 },
{ hidden: true }
);
以下操作隐藏已存在的索引:
db.restaurants.hideIndex( { borough: 1, ratings: 1 } ); // Specify the index key specification document
# or
db.restaurants.hideIndex( "borough_1_ratings_1" ); // Specify the index name
取消隐藏
db.restaurants.unhideIndex( { borough: 1, city: 1 } ); // Specify the index key specification document
db.restaurants.unhideIndex( "borough_1_ratings_1" ); // Specify the index name
细节
- 如果隐藏索引是唯一索引,则该索引仍将其唯一约束应用于文档。
- 如果隐藏索引是 TTL 索引,则该索引仍然会使文档过期。
- 隐藏索引包含在 listIndexes 和 db.collection.getIndexes() 结果中。
- 隐藏索引在对集合进行写入操作时更新,并继续消耗磁盘空间和内存。因此,它们包含在各种统计操作中,例如 db.collection.stats() 和 $indexStats。
- 要隐藏索引,必须将 featureCompatibilityVersion 设置为 5.0 或更大。
- 您无法隐藏 _id 索引。
- 不能 cursor.hint() 隐藏的索引。
在已填充的集合上构建索引
使用索引对查询结果进行排序
由于索引包含有序记录,MongoDB 可以从包含排序字段的索引中获取排序结果。如果此排序使用与查询谓词相同的索引,MongoDB 则可能会使用多个索引来支持排序操作。
如果 MongoDB 无法使用一个或多个索引来获取排序顺序,则 MongoDB 必须对数据执行阻塞排序操作
- 阻塞排序表示 MongoDB 必须在返回结果之前消耗并处理排序的所有输入文档。
- 阻塞排序不会阻塞对集合或数据库的并发操作。
从 MongoDB 6.0 开始,如果服务器在管道执行阶段需要超过 100 MB 的内存,MongoDB 会自动将临时文件写入磁盘,除非该查询指定了 { allowDiskUse: false }。
- 如果服务器需要超过 100 MB 的系统内存来执行阻塞排序操作,则 MongoDB 将返回错误,除非该查询指定了
cursor.allowDiskUse()。
使用索引的排序通常比阻塞排序的性能更好。
使用单字段索引排序
如果升序或降序索引位于单个字段上,则该字段上的排序操作可以是任一方向。
例如,在集合 records 的字段 a 上创建升序索引:
db.records.createIndex( { a: 1 } )
该索引可以支持对 a 升序排序:
db.records.find().sort( { a: 1 } )
该索引还可以以相反顺序遍历索引,从而支持 a 上的以下降序排序:
db.records.find().sort( { a: -1 } )
对多个字段进行排序
创建复合索引以支持对多个字段进行排序。
可以指定对索引的所有键排序,也可以指定对子集排序;但是排序键的排列顺序必须与其在索引中出现的顺序相同。
- 例如,索引键模式
{ a: 1, b: 1 }可以支持对{ a: 1, b: 1 }排序,但不支持对{ b: 1, a: 1 }排序。
要使查询使用复合索引排序,cursor.sort() 文档中所有键的指定排序方向必须与索引键模式相匹配,或与索引键的反向模式相匹配。
- 例如,索引键模式
{ a: 1, b: -1 }可以支持对{ a: 1, b: -1 }和{ a: -1, b: 1 }排序,但不支持对{ a: -1, b: -1 }或{a: 1, b: 1}排序。
排序和索引前缀
如果排序键对应于索引键或索引前缀,则 MongoDB 可以用索引对查询结果排序。复合索引的前缀是由索引键模式开头的一个或多个键组成的子集
例如,在 data 集合上创建复合索引:
db.data.createIndex( { a:1, b: 1, c: 1, d: 1 } )
然后,以下是该索引的前缀:
{ a: 1 }
{ a: 1, b: 1 }
{ a: 1, b: 1, c: 1 }
以下查询和排序操作使用索引前缀对结果排序。这些操作不需要对内存中的结果集排序。
| 例子 | Index Prefix |
|---|---|
db.data.find().sort( { a: 1 } ) | { a: 1 } |
db.data.find().sort( { a: -1 } ) | { a: 1 } |
db.data.find().sort( { a: 1, b: 1 } ) | { a: 1, b: 1 } |
db.data.find().sort( { a: -1, b: -1 } ) | { a: 1, b: 1 } |
db.data.find().sort( { a: 1, b: 1, c: 1 } ) | { a: 1, b: 1, c: 1 } |
db.data.find( { a: { $gt: 4 } } ).sort( { a: 1, b: 1 } ) | { a: 1, b: 1 } |
以下示例中,索引的前缀键同时出现在查询谓词和排序操作内:
db.data.find( { a: { $gt: 4 } } ).sort( { a: 1, b: 1 } )
在这种情况下,MongoDB 可以使用索引按照排序指定的顺序获取文档。如示例所示,查询谓词中的索引前缀可以与排序中的前缀不同。
索引的排序和非前缀子集
索引可以支持对索引键模式的非前缀子集执行排序操作。为此,查询必须在排序键之前的所有前缀键上包含相等条件。
例如,集合 data 具有以下索引:
{ a: 1, b: 1, c: 1, d: 1 }
以下操作可以使用索引来获取排序顺序:
| 例子 | Index Prefix |
|---|---|
db.data.find( { a: 5 } ).sort( { b: 1, c: 1 } ) | { a: 1 , b: 1, c: 1 } |
db.data.find( { b: 3, a: 4 } ).sort( { c: 1 } ) | { a: 1, b: 1, c: 1 } |
db.data.find( { a: 5, b: { $lt: 3} } ).sort( { b: 1 } ) | { a: 1, b: 1 } |
如上一操作所示,只有排序子集前面的索引字段必须具备查询文档中的相等条件;其他索引字段可以指定其他条件。
如果查询未在排序规范之前或与排序规范重叠的索引前缀上指定相等条件,操作将无法有效使用索引。
- 例如,以下操作指定的排序文档为
{ c: 1 },但查询文档不包含前面索引字段a和b的相等匹配项:
db.data.find( { a: { $gt: 2 } } ).sort( { c: 1 } )
db.data.find( { c: 5 } ).sort( { c: 1 } )
这些操作不会高效地使用索引 { a: 1, b: 1, c: 1, d: 1 },甚至可能不会使用索引来检索文档。